I haven’t been good at keeping this blog alive and maybe I’ll come around to explaining what I’ve been up to.
But at least I’d like to share my obligatory list of books. Again, these are the books I read that year, not those written in that year.
Influenced by the start of the Ukraine war, my reading this year took a dark turn: I read a lot on military history, strategy and war memoirs.
“The Strategy of Denial: American Defense in an Age of Great Power Conflict”, by Elbridge Colby.
This book lays out a suitable US strategy of denial (= containment) of China. Colby tries to derive from first principles the current US strategy of restricting China’s sphere of influence and, most importantly, stopping China from subduing Taiwan.
Not the best-written book, I think Colby tries a bit too hard to sound scientific and theoretical. But I think worth a read given the US-China rivalry will likely dominate politics of the coming decades.
“2034: A Novel of the Next World War”, by Elliot Ackerman und Admiral James Stavridis.
This is a timely work of fiction: The book plays out how a Chinese-US war might go. The narrative is a bit flat, but it does feed the imagination.
I have absolutely no clue of how wars are being fought or the technical background involved. But I found the scenario here a tad unlikely: China somehow finds a red button that blocks all US communications at the start of the war.
The book made a splash, also given that the two authors are former high-ranking US soldiers.
“The Case Against the Sexual Revolution: A New Guide to Sex in the 21st Century”, by Louise Perry.
A thought-provoking book. Some of what stayed with me were the comparisons of physical strength of men and women: Apparently the average man has twice the upper body strength as the average women. Also:
In hand grip strength, 90 per cent of females produce less force than 95 per cent of males. In other words, almost all women are weaker than almost all men, and any feminist analysis of the power dynamic between men and women has to begin with the recognition of this fact.
She also did a good job of describing situations in which women have to be fearful of men and how a woman feels like when in them.
“Urban Warfare in the Twenty-First Century”, by Anthony King.
This was the first book I read after the Ukraine war started, when everyone expected Russia to quickly occupy most of the country and for the fight to drag on in the cities.
It didn’t turn out that way, but I took a lot away from this book: The most important thing being the radical and definite change in warfighting with the rise of nuclear weapons. Armies used to be gigantic accumulations of millions of men. With nuclear weapons, such armies are just not necessary anymore. You can spare the cost and still be able to defend yourself credibly.
Because armies are so much smaller now, there is much more fighting for smaller strategic points within cities. The huge armies of the past mostly met outside of cities.
The big “downside” (from an imperialistic dictators point of view) is that it’s not possible to fight wars in the old ways anymore with the current size of armies. The battle for Berlin lasted only two weeks, with an army of 2 million Soviets surrounding Berlin and then fighting their way in. The battle for Stalingrad, which King refers to as “the greatest urban battle in history” lasted for only three months (the main part of it at least).
Compare this with Russia’s invasion force in Ukraine of about 200,000 soldiers and you see how different things are.
Other factors in how wars have changed are: A lower tolerance for casualties driven partly by an increase in our humanistic ideals (one would hope) and by the greater value of the individual soldier due to smaller armies (one has to fear). Also there has been (economically speaking) an increase in capital involved (i.e. more fancy gear to be used per soldier).
“Out of the Gobi: My story of China and America”, by Weijan Shan.
Shan is a successful businessman nowadays, working out of Hong Kong. He grew up in Beijing and got entangled in the madness of the Cultural Revolution. He “served” (?) a stint of several years living in the harshness of the Gobi desert. He managed to immigrate to the US and do a PhD there.
It’s an impressive book, but understandably silent on the machinations of the Chinese state after 1990, such as lack of democratic progress, treatment of minorities and its stance towards Taiwan.
“Convictions: A Prosecutor’s Battles Against Mafia Killers, Drug Kingpins, and Enron Thieves”, by John Kroger.
Kroger had been a marine, then chased the Mafia in New York City as a prosecutor and later worked on the Enron case. I greatly enjoyed this book.
I liked this line:
Mafia families have one profound organizational weakness: no clear rules for succession.
And this:
In law enforcement, a small but appreciable number of men run the risk of “moral capture.” They spend so much time living in the underworld, with crooks and crooked informants, they come to adopt its perspective. Almost imperceptibly at first, they begin to envy […].”
And this:
Criminal groups, in my experience, rise and fall in the same way. To survive, a criminal organization must be more than “good at crime” in some abstract sense. It must also exist in an economic and social environment that favors the particular organizational structure, type, and style of crime it practices. A criminal group that comes to power in one era, when conditions favor its existence, may die out when conditions change.
The mafia stopped being successful when the conditions changed: More credit options for poor people (apart from loan-sharking) and no more discrimination against Italian immigrants (leading to recruiting problems for the Mafia).
Kroger gets the mix right of being a successful hero, but being self-deprecating enough for it to read as an excellent memoir.
I was convinced that whenever I took a break from work—every baseball game, every dinner out, every lazy morning in bed—I was increasing the odds that a guilty defendant would escape arrest or conviction. […]
For two solid years I worked eighty hours a week. I busted a lot of drug dealers, and in return I was accorded a fair amount of professional independence. Jodi, my boss, let me do what I liked. I wore jeans and black Converse high-tops to the office instead of suits, spent tens of thousands of dollars on investigative trips, and dumped cases I did not like on junior, or less favored, colleagues. But I paid in other ways. On weekends you would typically find me at the office, poring over reports or examining evidence. Some afternoons I was so worn out I fell sound asleep in my chair, feet propped up on my desk. Typically, I got through the workday only because I was buzzed out on caffeine—kind of ironic, given my narcotics assignment. I was a good prosecutor but a limited human being.
This is a book I might re-read at some point.
“A Certain Idea of France: The Life of Charles de Gaulle”, by Julian Jackson.
This book cover a part of history I knew to little about and reading it was a pleasurable way to fill it. I liked the fact that at more than 900 pages, so it didn’t have to leave anything out.
Overall, de Gaulle comes out as an impressive, but flawed character. Democracy wasn’t the most important thing for him, but France’s “grandeur” - it’s standing in the world.
And in this he did succeed: I’ve always been puzzled why France is counted as one of WW2 “winning powers” and why it occupied a slice of Germany, got a permanent seat at the UN security council and so on.
“With the Old Breed: At Peleliu and Okinawa”, by Eugene Sledge.
Sledge served as a US marine during WW2, fighting on Guadalcanal, Peleliu and Okinawa. He describes his experience during the war. He started writing the book right after the war, but it was only published in 1981.
It lacks any romanticism for war and describes the immense horrors he experienced. Highly recommended.
It’s the best book on what it feels like to be a soldier in a high-intensity fight, right after “Im Westen nichts Neues”.
A factoid that stuck with me was that he didn’t sleep a single night in a real house during the whole stay in the Pacific. Only ships, tents and open nature.
“Tagebuch der Anne Frank”, by Anne Frank.
I’ve only come to read it now and it touched me deeply.
“Undaunted: My Fight Against America’s Enemies, at Home and Abroad”, by John O. Brennan.
Brennan tells the story of his career in the CIA and the White House. There’s obviously a lot he cannot tell, but I found the organizational aspects of the intelligence work interesting. It reminded me of my work in management consulting, preparing documents for cascades of meetings. He also explains how the CIA’s organization was restructured, from two silos of analysis and operations to “mission centers” combining both, focused on regions or topics.
I think the field of organization is quite underrated, but getting it right is fundamental to firms’ or institutions’ effectiveness and employee happiness.
“Inspired: How to create tech products customers love”, by Marty Cagan.
The book covers the topic of “Product Management”.
It’s a strange subject, because the terminology of product management (“MVP”, “to ship a product”, …) has seeped into every day business lingo. Cagan is very precise in his vocabulary and sheds light on terms that are often used interchangeably.
Cagan covers product disvovery and delivery, defines an “empowered product team” and is full of pieces of wisdom. His blog is also good.
“Project Hail Mary”, by Andy Weir.
Problem solving porn.
Weir’s wrote “The Martian” before which has also been made into a movie. I liked this new book even better, it’s broader and made me think more.
The book “Range: Why Generalists Triumph in a Specialized World”, by David Epstein (2019).
Our world is becoming more complex with an abundance of available information and global networks linking organizations and people with each other.
In the face of rising demands, you might choose to quickly specialize. David Epstein, a journalist, argues in his new book for the opposite approach. Himself clearly a generalist (a former scientist working as sports journalist and writer) he wrote this clever book arguing in favor of being a generalist.
Wielding an alphabet soup of one-letter abbreviations for different types of specializations (I shaped, T shaped, Pi shaped or L shaped), he draws on a wide range of studies, analogies and biographies to make his case. Soviet scientists, musicians without formal training and Japanese inventors appear in his well-written narrative. He shows how successful people were curious about developments in adjacent fields and how they frequently changed tracks ignoring sunk costs.
He emphasizes the need for maximizing match quality which is the quality of the fit between what you do and what you are good at and enjoy doing. So aim for activities that have high “exploration value” for yourself - new situations in which you find out what you enjoy and what you’re good at. Assign high values to “real options”, so prefer the possibility to change your mind later.
***
Epstein focuses mostly on people’s jobs, so what they do in their work. But that’s only one side of the coin, the other side is what people consume and what they do in their spare time. Here, too, you can be more generalist or more specialized.
You can do what other people do, watch the same movies, plan your vacations at the same places, but increasingly people do the opposite. Researchers have documented a rise in “niche consumption”, so people are enjoying rising product varieties thus more intensely tickling their taste buds.
***
What Epstein doesn’t quite explain is why some people become generalists and others don’t. Why are some people more curious and creative, more accepting of uncertainty?
One explanation might be a person’s personality. In the Big 5 personality model , the “openness to experience” trait might be a good predictor. But I find it unlikely (and it would be uninspiring) if personality (or “talent”) was the sole reason for people to become particularly productive or innovative.
I think another candidate are external factors that just happen and force people to change what they do.
A case in point is the situation studied by Shaun Larcom, Ferdinand Rauch, Tim Willems. In their paper (pdf), they study what happened around the 2014 tube strike in London:
During a two day period, some of the underground connections were closed. Travelers had to find different routes through the system. And these exist: For example there are 13 reasonable ways of traveling from King’s Cross to Waterloo.
The strike only affected the tube network, so travelers might also have switched to taking the bus, walking, riding a bike or taking a taxi.
The authors tracked 17 thousand travelers whom they classified as commuters and for whom they have 20 working days of data.
They show that many commuters found a better route during these days of forced experimentation, which they stuck with even after the strike ended. They estimate that around 5% of commuters did not travel on their optimal route before the strike occurred. They even show that the loss of time during the strike is easily compensated by later time savings from having found a better route.
You could also phrase the findings of Larcom et al. as follows: They gained range in their knowledge of the transport network and that’s why they improved their commuting habits.
***
Epstein himself ends with an optimistic message and writes that we should not become discouraged:
[O]ne sentence of advice: Don’t feel behind. […] Compare yourself to yourself yesterday, not to younger people who aren’t you. Everyone progresses at a different rate, so don’t let anyone else make you feel behind. You probably don’t even know where exactly you’re going, so feeling behind doesn’t help. […] [Focus on] match quality, start planning experiments. Your personal version of Friday night or Saturday morning experiments, perhaps. […] Finally, remember that there is nothing inherently wrong with specialization. We all specialize to one degree or another, at some point or other.
In computer science, breadth-first is a design pattern to describe an algorithm which first tries many different paths and later digs deeper. I think it’s a fitting metaphor to plan a career - and maybe a life.
Here are 10 books I most enjoyed reading this year - in reverse order:
“Facebook: The Inside Story”, by Steven Levy.
It covers Zuckerberg’s growing up and the fascinating story of how Facebook was founded. The reason is was initially successful was that it was very open within a limited group (Harvard, then college campuses):
Other scenarios would give Facebookers the shivers. Could an adult “friend” a high school student? Wouldn’t that be creepy? Or just uncool? “Facebook would be taking this service that college students considered their own, and opening it up to a bunch of randos,” says one employee from the time. “The thinking of folks at the time was that older people were just going to make it lame.”
Which is what happened.
The addition of the newsfeed shaped it profoundly:
What Facebook simply hadn’t realized about the News Feed was that pushing information to people was qualitatively different from publishing it on someone’s home page. (More accurately, it had shrugged off the early warnings to this effect.)
[...]
In a breathtakingly short period of time, people got used to the idea that the stuff they did on Facebook would wind up spread all around Facebook.
[...]
So it was that the simplest of features boosted Facebook’s business, gave users an easy way to express themselves, and set the company on a disturbing course of overemphasizing trivial or angry content.
I found it most interesting how Zuckerberg developed an approach for successfully taking over other social networks. Yahoo tried taking over Facebook, but stalled very late and tried to renegotiate. In response, Zuckerberg developed a “shock and awe” tactic of showering founders with attention and raising the price way above their expectation. It has worked well for their Instagram and WhatsApp acquisitions.
I also enjoyed the part on Cambridge Analytica - I hadn’t been aware of how much went wrong within Facebook in handling this scandal.
“Uncanny Valley”, by Anna Wiener.
Wiener’s path through Silicon Valley. It’s written in a strange outside voice, like an alien ethnographer studying a group of humans. I found it very enjoyable and insightful, though I disagree with her with on most of her value judgments.
They [the programmers] talked about achieving flow, a sustained state of mental absorption and joyful focus, like a runner’s high obtained without having to exercise. I loved that they used this terminology. It sounded so menstrual.
Wiener works as a non-technical employee at a number of startups in San Francisco. She describes how she was often looked down upon for not being able to code. She was better at communicating and helping customers. In other industries (consulting?) these would be the more important skills and the higher status would be hers.
“The Ride of a Lifetime”, by Robert Iger.
Iger’s fascinating story rising to corporate heights at ABC and Disney.
Iger stresses his hardworking style, how he “could outwork anyone else” or how he took his “first ever” two week vacation when his son was two years old. It’s not something I find surprising from my own experience with managers, but it’s not very inspiring.
The book offers a lot on leadership. Iger emphasizes the importance of patiently doing the job you have well and then looking out for opportunities to take on more. On the flip-side, to grow people you should want people to be eager to rise up and take on more as long as “dreaming about the job they want doesn’t distract them from the job they have”.
I found it interesting how personal many of the key decisions such as corporate takeovers were. In this words: “Looking back on the acquisitions of Pixar, Marvel, and Lucasfilm, the thread that runs through all of them […] is that each deal depended on building trust with a single controlling entity.” This is similar to the “shock and awe” tactic Zuckerberg developed.
“Vom Ende der Einsamkeit”, by Benedict Wells (in German).
Three siblings become orphans when their parents die in a car crash. They take very different paths in life. Beautifully written.
“The End of Everything: (Astrophysically Speaking)”, by Katie Mack.
Really great book on the universe and cosmology. The book is on our current best theories on the end of the universe. (Humanity dies out in all cases.)
I learned a lot from this book because of the level effect: I know little about astronomy and cosmology, so its amazing to see how much is known in this field. I had a similar effect reading a book like “Guns, Germs and Steel” where I learned about archeology and linguistics.
I especially liked Mack’s explanation of how distances can be measured in space or why we still see background radiation when we zoom out farthest into any spot in space.
“The Rise and Fall of the Dinosaurs”, by Steve Brusatte.
They had feathers and their last living descendants are birds. A fascinating book, simply because time scales are so incredible. Millions of years pass, species change, continents shift.
“Mind Without Fear”, by Rajat Gupta.
Gupta is the former head of McKinsey & Company (my employer at the time of writing) and he was indicted for insider trading. He wrote this memoir in which he argues for his innocence.
He tells a fascinating story of his origins in India and his rise through the firm. He didn’t take out clients to fancy alcoholic dinners and didn’t play golf, but instead invited them home for his wife’s home-cooked Indian food. His colleagues once wrote down the following “Eight Laws of Rajat Gupta” for him:
If someone else wants to do it, let him
If you have ten problems, ignore them – nine will go away
Being there is 90% of the game
You can’t push a noodle; find the right angle and pull
The softer you blow your own trumpet, the louder it will sound
There is no such thing as too much work or too little time
Listening takes a lot less energy
When in doubt, invite them home.
He was head of the firm in the 90s and there were many strategic decisions to be made. Some consulting firms founded investment branches (like Bain Capital) and there was a discussion to go public (like Goldman Sachs, also a former partnership). During his time at the top, staff doubled and revenue tripled.
But then the story turns: Gupta founded a hedge-fund with Raj Rajaratnam and had phone calls with him after key events around the 2008 financial crisis (Gupta was on Goldman Sachs’ board). After the board meeting in September 2008 where it was decided that Warren Buffett would buy Goldman stock, he called Rajaratnam seconds later and Rajaratnam bought Goldman stock right after. However, there’s no smoking gun evidence that he told Rajaratnam any insider information or that he benefited financially from it. (Also see this summary.)
My feeling is that even if he hadn’t been part of insider trading, the things that Gupta admits overstep enough lines to warrant the loss of reputation, his board seats and probably a financial fine.
Gupta went through grueling years of being accused, losing his position and many of his relationships. He spent 19 months in prison and says that he paid a 20 million US dollars fine.
I found his explanation of his time in prison the best part of the book. It shows Gupta as a human, empathic person trying to survive in a hostile environment. He was even sent to solitary confinement for the silly “crime” of having a special cushion for his bad back.
Overall, I find the punishment too harsh for the crime. After all, the evidence was circumstantial, it’s a white-collar crime and it’s unclear that he ever benefited from it financially. I don’t find it necessary for him to have gone to prison at all. The financial penalty, the loss of his reputation, the years spend being dragged through the courts seem enough to me.
Another lack of judgment is how Gupta chooses to tell his story. In his world view, he’s a brilliant person who got cheated by other people. He doesn’t apologize and writes mean comments on some of the people involved and former colleagues.
“Very Important People”, by Ashley Mears.
The author is a sociology professor in Boston and a former fashion model. She wrote this amazing book on an extreme niche of global partying: How the most expensive clubs use “promoters” to bring fashion models to their parties. Super-rich clients pay thousands of dollars for these tables for a night and promoters then bring the models to these tables such that rich men can surround themselves with pretty women:
Sex between girls and clients is not the main point of having so many models in attendance; rather, it is the visibility of sexiness in excess that produces status. […] High-status places are surely pleasurable in themselves, in part because being high status feels good.
[...]
It’s an arrangement that looks like sex work. But it feels qualitatively different than sex work, because the club does not sell the company of girls directly. Rather, clubs sell marked-up bottles of alcohol that usually result in the presence of models, typically brought there by promoters or arranged by the club managers who ensure clients are surrounded by beautiful women. Paying for women outright is stigmatized, but there is nothing wrong with paying for drinks. By bundling expensive bottles with beautiful girls, clients get the illusion of authentic company with girls. […] Footnote 25: Hiring a broker is a common means of obfuscating a stigmatized exchange.
This might make for an obscure read, but I found the lessons quite broad. For a probably not-so-small share of humanity, this is considered the peak of luxury and exclusivity. Yet it falls apart when you see what’s behind it. And the parties she describes sound very unappealing - to me at least.
The most interesting people are the promoters themselves. They’re often from poor minority backgrounds, yet are surrounded by young beautiful women and mostly rich white older men. They earn good money, but it’s almost impossible for them to become like their rich clients.
But if anything looks like sex work in the VIP world, it’s not the sex between clients and the girls. It’s the sex between the promoter and his girls.
I like how fair and ambiguously Mears treats the materials. One point she considers are particularly unfair is that the models aren’t paid:
There was one gift that promoters rarely gave to girls: money. Cash payment was notably absent from promoters’ strategies for recruiting girls. Promoters frequently offered to pay models’ cab fare to and from the club (about $20), but this money was always explicitly earmarked for cabs, lest there be any confusion about what she is doing out. Sometimes a promoter might share a windfall of cash with his favorite girls, but it was expected this would be used for shopping sprees and not considered payment.
While the surroundings are super gendered and unequal and models don’t get paid for their labor, all participants seem to enjoy it and like being part of it. I think a useful correction to come out of it might be for people to assign lower status to these kind of clubs and parties than what is currently the case.
Also see this interview between Mears and Tyler Cowen.
“Children of Ash and Elm: A History of the Vikings”, by Neil Price.
There is a lot we don’t know about the vikings. This author tells us what we do know.
They were polygonous, haven’t left us a lot in writing, buried incremendible riches such as silver and ships. I really enjoyed how Price combines insights from many different sources, such as archeology (especially burials), medieval Icelanding poems, Arabic travel memoirs. He even mentions how there is a specific kind of mice species living on a Portuguese island in the Atlantic ocean, showing that the Vikings must have traveled there.
He also has a cool way to introduce the vikings: The book starts with the most difficult part - how vikings viewed the world, their ideas of afterlife, their views of the body and the four different kind of souls live within it. The viking age started off with a large crisis in roughly 400-600 CE driven probably by volcanoe eruptions in combination with plague leading to lower fertility, population shrinkage etc. The author hypothesizes that this shaped the vikings’ world view: That there world would at some point end and that doom was certain (Fimbulwinter, Ragnarök).
It’s very fascinating to see what we can find out from these historical sources. There are even Icelanding poems telling of the journeys to Vinland (America).
“Pachinko”, by Min-Jin Lee.
A wonderful novel following a Korean family over several generations, starting before World War II. The author is an Korean American and the book was originally written in English.
“Because it cannot.” There was nothing else he could think of, and he wanted to spare her the cruelty of what he had learned, because she would not believe that she was no different than her parents, that seeing him as only Korean — good or bad — was the same as seeing him only as a bad Korean. She could not see his humanity, and Noa realized that this was what he wanted most of all: to be seen as human.
As the time I’ve spent in my job at McKinsey is nearing two years, I want to reflect on how it’s been and how I’ve changed.
I went into this job full of excitement, anxiousness and with some sadness. I was excited to get to know this firm, the world of business and to apply what I’d learned. The excitement mixed with anxiousness as I pondered what projects I would work on, how my colleagues would be and how I’d adjust. I was also sad, because I didn’t feel completely ready to leave academia. I liked it there and leaving felt like admitting failure.
***
My best memories over the last two years come from having a good time with people, often in some distant place. My worst memories are from when relationships in the team were broken and I felt like I worked too much with too little effect.
While I’ve learned some new technical skills, I found it more important to improve my general way of working and communicating. I needed to get the balance right between being thorough and being pragmatic, between questioning assumptions and accepting guidance from others. I learned a new vocabulary to speak about my work and became more at ease with sharing unfinished work products to ask for early feedback. I learned to better synthesize large amounts of information and how to mine my pool of prior experiences to propose the next step in an analysis. Most of all, I needed to accept criticisms and to work on my faults.
I’m thankful of how varied the projects I worked on have been. My proudest moments happened in short, intense work episodes during which I had a strong sense of effectiveness: That I was the right person at the right place and my work made a difference.
***
I’m still the same person I was when I went into this job. My basic opinions, preferences and relative strengths have hardly changed. I only realize what I’ve learned when I meet somebody who doesn’t know something, like a new starter who makes the same mistakes I made before.
To keep balance, it’s been important for me to keep in touch with people outside my job and to stay focused on what I want in the long run. Incentives in the business world can let you lose sight of the boundary between what’s investment and what’s consumption. You collect airline miles and hotel points, go to “trainings” (more like mini-vacations) in nice places and eat dinners in fancy restaurants. But consumption is not durable and while expectations rise, memories fade.
***
Two years in, the feelings of excitement, anxiousness and sadness are gone.
My work has become more routine, as I find myself in situations I’ve been in before. The uncertainties about my job are less and I find it easier to start into new projects and know what to expect. A residue of uncertainty has stayed, as I’ll never know what the next project will bring or if I’ll like being around the people I’ll work with.
The sadness about leaving academia has fallen with every month since I stepped out. About half a year ago it crossed the threshold from where I’m finding it hard to imagine going back. I like that work outside academia is faster and has direct effects. It’s less thorough, but that’s ok. I realized that many of the parts I enjoyed in academia weren’t specific to it, such as exploring new topics, analyzing data or presenting results.
What’s next I don’t know. I enjoy my job and have no plans for a change. But I know that the nagging feeling of needing a change will return and I won’t fight it when it does.
When thinking of successful startup founders, many people have Mark Zuckerberg, Steve Jobs or Bill Gates in mind - in general a young college-dropout working from a garage in Silicon Valley.
In a new paper (pdf) Pierre Azoulay, Benjamin F. Jones, J. Daniel Kim and Javier Miranda attack this misconception of young founders being more successful than older ones.
The authors take comprehensive census data for the United States and show that the average age for successful founders is in the 40-45 year range. As they write:
The mean age at founding for the 1-in-1,000 fastest growing new ventures is 45.0.
Details
They show in clever ways that this unexpectedly high age average also holds for high-growth startups and those in the tech industry, by using ex ante and ex post measures of growth and tech specialization.
Ex ante, they measure the industry a founder is in, whether the firm received venture capital (VC) funding and whether the firm holds a patent. Ex post, they are able to measure employment and sales growth for these firms 3, 5 and 7 years after founding and they measure which firms “exit successfully” (meaning they are sold or go public). The average ages are similar for all these different subgroups.
Azoulay et al. also show that the results are not just driven by the fact that middle-aged founders are more common thus pushing up the age average. Instead they show that middle-aged founders are more likely to succeed.
One reason for this might be the importance of prior experience. They show that the probability of success (being one of the 1-in-1,000 fastest growing firms) doubles after three years of work in the relevant industry.
The authors also discuss extreme outliers (Zuckerberg etc.) and provide the following verdict:
With [keeping the anecdotal type of evidence] in mind, however, the patterns may suggest a potential reconciliation between the existence of great young entrepreneurs and the advantages of middle age. Namely, extremely talented people may also be extremely talented when young. These individuals may succeed at very young ages, even when people (including these young successes) get better with age. Thus there is no fundamental tension between the existence of great young entrepreneurs and a general tendency for founders to reach their peak entrepreneurial potential later in life.
Discussion
Time period: My biggest criticism is that startups only make it into the sample used for the most important analyses if they were founded in 2007-2009. This is a short sample to start with, but more importantly this was also the time of the Financial Crisis.
During this large recession, investors might have stopped funding and banks might have stopped giving credit first to the more speculative and riskier firms run by younger people. This might bias the results to older founders. Table A4 shows averages separately for the different years, but all these years are the aftermath of the Financial Crisis, so that doesn’t address this problem.
You could also think that there might be some cohort effect of all the 40-year olds in those years having been young in the 90s when they might have started their first companies during the first Dotcom gold rush.
Measures of success: A second criticism I have is that this paper defines employee and revenue growth as the key measures of a startup’s success. The most clean measure would is a startup’s value, which is a more complete summary of a firm’s ability to generate profits in the future. This is difficult to measure even for established firms, so I understand why the authors did not do this.
However, this can lead to extreme examples where the author’s measures make less sense. Take the example of WhatsApp: It had only 50 employees in early 2013, but was acquired by Facebook a year later for 19 billion USD. (To be fair, with 400 million users in late 2013 and each paying a dollar for the product a year, revenues would already have been impressive).
On balance: But in total, I think this is an excellent paper. It hits a sweet spot of 1) discussing a relevant topic, 2) bringing novel results that shift my views and 3) being well-executed and thus trust-worthy.
I also find it somewhat comforting to think that you don’t have to rush into entrepreneurship with a half-baked idea, but that there are advantages to starting a firm later in life.
Playing with the data
Most of the data is confidential, so the authors can’t share it. But they’ve also collected a list of companies named by media and VC organizations that were considered particularly promising and the age of their founders. This data we can play with.
The data we need are stored in four files: Matrix.dta, Sequoia.dta, TechCrunch.dta and Magazines.dta. Instead of downloading each and combining them, we can do this only writing the code once.
This defines a function which unzips the relevant file, imports the Stata files
and adds a column to describe the data source organization:
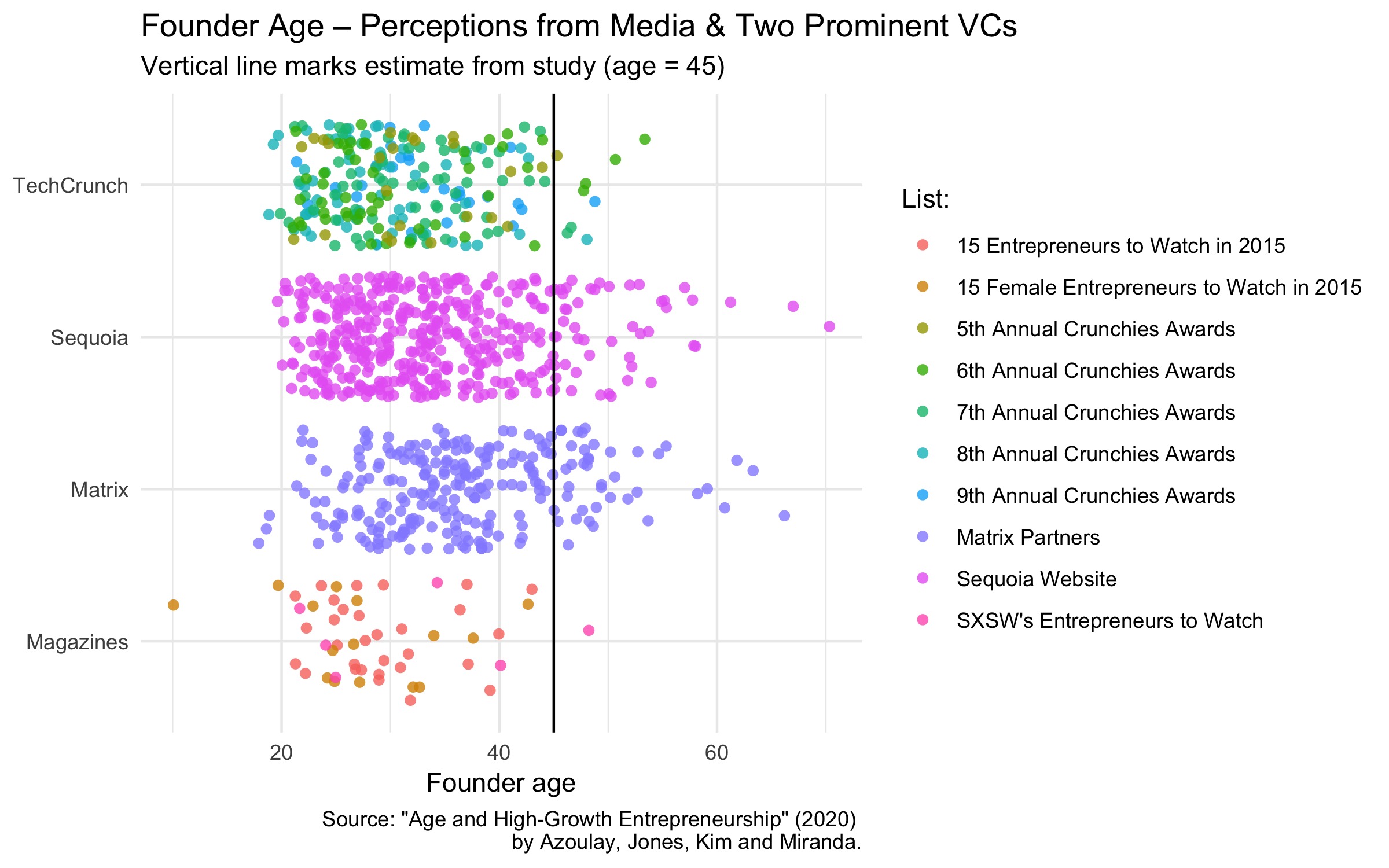
The resulting dataset perceptions holds the name of the organization, the name of the list they created, the age of the founder and the company’s name:
Plot the age of the founders and add a line marking the paper’s estimate of
45 years against it:
ggplot(perceptions,aes(age,org,color=list))+geom_jitter(alpha=0.8,stroke=0,size=2.2)+labs(title='Founder Age – Perceptions from Media & Two Prominent VCs',subtitle="Vertical line marks estimate from study (age = 45)",caption='Source: "Age and High-Growth Entrepreneurship" (2020)
by Azoulay, Jones, Kim and Miranda.',y=NULL,x="Founder age",color="List: ")+theme_minimal()+geom_vline(xintercept=45)
If the public perception of founders’ age was in line with the estimates from this paper, we would expect the cloud of point to be centered around the black line.
The fact that these points lie mostly to the left of the line shows that public perception favors younger founders.
Reference
Azoulay, Pierre, Benjamin F. Jones, J. Daniel Kim and Javier Miranda (2020). “Age and High-Growth Entrepreneurship.” American Economic Review: Insights. (doi)
In her memoir “Uncanny Valley”, Anna Wiener tells the story of how she went from a job in the NY publishing industry to work for Silicon Valley startups.
Wiener describes her years working in different startups and in doing so chronicles the vibe and the good and bad aspects of tech culture in San Francisco. She then quit her job and is now a writer for The New Yorker where she still covers the tech sector.
The last tech company Wiener worked for is a large company providing a site for collaborating on code. She doesn’t name it, but it is without doubt Github.
There, she learns about remote working culture. I read this book at the beginning of March this year, when Corona less acutely affected my life and work than it does now. Then, I found the contrast between work at Github and at what saw at different companies very pronounced.
This is Wiener on Github’s remote working culture:
Everyone was encouraged to work how, where, and when they worked best—whether that meant three in the morning in the San Francisco office, referred to as HQ, or from inside a hammock on Oahu.
[…]
To ensure that all employees were on equal footing regardless of geography, the majority of business was conducted in text. This was primarily done using a private version of the open-source platform, as if the company itself were a codebase. People obsessively documented their work, meetings, and decision-making processes. All internal communications and projects were visible across the organization. Due to the nature of the product, every version of every file was preserved. The entire company could practically be reverse engineered.
[…]
Our remote coworkers had wants. They often spoke of feeling like second-class citizens. As the company became more corporate, the culture had gone from remote-first to remote-friendly.
As the pandemic forces me too to work from my home, some of those aspects start to feel familiar: I find chat programs more useful than before. For me they’re not about documenting my work, but about asking small questions that I would ask someone directly when I’m in a room with them, but that I might not call them for.
There are also differences: The tech sector is more laid back than other sectors and so far we haven’t started taking calls in our bed or a hammock, even for internal calls.
My reading this year fell mainly into three buckets: Memoirs, novels by Sally Rooney and books by the historian Thomas Madden.
These were my favorites:
“Maoism: A Global History”, by Julia Lovell. Explains how maoist thought and actions by the Chinese government influenced movements in other countries. Not much talked today - especially by the Chinese government.
“Aladdin: A New Translation”, by Yasmine Seale. This is the first documented Aladdin story, intriguingly first published in France in the early 18th century. I wonder about the morality of it: If you had some tool (a Jinn in this tale) that could get you whatever you want, I don’t think the acceptable way to behave would be to kill a magician, get the biggest house full of diamonds and force the terrified princess to sleep in your bed.
“Writing My Wrongs”, by Shaka Senghor. He describes life on the streets of Detroit, the murder he committed, 19 years in prison of which he spent 7 years in an isolation cell (4 years in a row).
“The Education of an Idealist”, by Samantha Power. I liked the start of the book more than the part when she became ambassador. I think the legacy of her administration’s foreign policy doesn’t hold up well and I didn’t learn much from her time at the UN. They seemed to spend a lot of time on symbolic gestures, but got the big things on Syria wrong. I much prefered her very personal story of her long path through war journalism, academia and government.
“Conversations with Friends”, by Sally Rooney. There are lead characters that I would have guessed to relate better to than a female bisexual Irish poet, but this is a book I knew from the first page I would enjoy and read to the end.
“Shoe Dog: A Memoir by the Creator of Nike”, by Phil Knight. Fascinating story of the founding of Nike, touching on how the early running subculture and post-war Japan. Knight is a different founder from those we have in our minds today: He first finished his MBA and worked in accounting when he needed funds for his business. He had very supportive parents and also turned to them at the beginning for money. (Olli’s review)
Samantha Power is the former US Ambassador to the UN under Obama, a Harvard professor and a former war journalist reporting from 90s Bosnia. In her recent memoir, “The Education of an Idealist”, she describes her upbringing in Dublin with an alcoholic father, migrating to the US and her path through journalism, academia and government.
I like her explanation of the different modes of working in journalism/academia vs. government.
Mode 1
In her early twenties, Power worked as a journalist in wartime Bosnia. She reported from Sarajevo while it was under siege and published many articles in large newspapers and magazines. She learned to write in an engaging way which helped her later, when she became an ambassador to bring the stories of individuals to her official UN meetings, to make other diplomates relate to them and their suffering.
She enjoyed her independence, the travel and the attention and status from seeing her name published in the New York Times or the Washington Post.
But she missed the opportunity of shaping events herself. When she interviewed politicians, she would often think: “I would rather be on the other side of the table.”
So she decided to join law school:
Jonathan Moore, the former US diplomat and refugee expert I met working at Carnegie, had become someone I turned to at critical moments. With school beginning at the start of September, I needed to make a final decision, so I telephoned him and asked what I should do. Jonathan didn’t hesitate. “Get the hell out of there,” he urged me. “You need to break out of the compulsion for power, glory, ego, relevance, contribution. Get out. Get out before it gets you, and you forget what got you in.” I didn’t think self-consciously about power, glory, and ego, but Jonathan knew I didn’t mind seeing my name in print.
After her graduate studies, she became a professor of human rights law at Harvard Kennedy School. At the same time, she published “A Problem from Hell: America and the Age of Genocide”, for which she won the Pulitzer Prize.
Mode 2
Power learned about Obama, the new Senator from Illinois, from his DNC speech, reached out to him through friends and joined his team. She entered his administration to work at the National Security Council in a role focused on managing contacts with the UN and keeping an eye on human rights issues.
But she was frustrated that colleagues would not listen to her, that she could not travel as she liked and that her initiatives would come to nothing. She felt like she wasted her time when she and her colleagues would spend a long time marking up each other’s word documents. She needed to learn the vocabulary, such as that stepping over a level in the hierarchy was a “process foul”.
Time also became more precious:
The aspect of government that I had least appreciated before I joined was the importance—and shortage—of “bandwidth.” So much was going on in the world on any given day that one could easily lose an afternoon editing language in various press releases. Mort, my longtime mentor, urged me to prioritize, helping me understand my days as analogous to my mother’s when she worked in the emergency room.
Suddenly she was in the group making the decisions:
[A mentor] often dispensed wisdom on how government worked, and told me I should not have waited until a high-level meeting had ended to make my point. “Listen,” he said firmly. “If you hear nothing else, hear this. You work at the White House. There is no other room where a bunch of really smart people of sound judgment are getting together and figuring out what to do. It will be the scariest moment of your life when you fully internalize this: There is no other meeting. You’re in the meeting. You are the meeting. If you have a concern, raise it.”
In her words, she “did not yet have the relationships, the clout, or the mastery of bureaucratic processes [she] needed to maximize [her] impact.”
Putting it together
It took her some time and the advice from more experienced colleagues such as Susan Rice to get up to speed and learn to deal with her frustations.
To become effective, she used three strategies:
Keep an eye on the big picture: Don’t forget the long run even though short-run attention is crowded out.
Build a network: She created a weekly “Wine & Cheese” women group to share stories and get advice. And she also played basketball which helped her to get to know the male colleagues in the White House better.
Work on smaller projects: These don’t get top leadership attention and are easier to have an impact on.
I enjoyed reading her story and can relate to it. Working in hierarchies is something you have to learn. I found life as a researcher more free, less structured and more bottom-up. I was expected to search for my own research ideas and I could collaborate freely.
It’s quite different for me as a consultant. Our teams work embedded at the client in large hierarchies, so there are more stakeholders to inform and align with. The target audience usually has limited “bandwith”, as your project is only one of many that concerns them. That’s why it’s important to understand the process and to be concise and accurate in your communication.
While the first mode of working is more conducive for being creative, I now realize I could sometimes have been more effective in academia using some simple strategies. A simple, “end of month” email with what I did the last month and what I planned to do in the next would have gone a long way of keeping my supervisors in the loop, even when we couldn’t meet face to face.
In other areas, I think researchers use the same tools successfully already. Most writing guides for papers or presentations already advise to be “top down” - to put the message at the beginning and the details at the end.
In the end, the two modes of working are very different, but there is a time and place for both.