VoxEU gobbledygook
We’ve written a VoxEU column for our patent paper, which you can find here.
Overview statistics
When I started writing this article I became curious how a typical VoxEU column looks like. So I scraped the archives and looked at some statistics. Here they are (as of November 15 2017):
- After some cleaning, there are 5633 columns from January 2008 to November 2017.
- The mean number of page reads of columns is 20,600 (median: 16,600).
- The mean number of authors is 2.1 (median: 2). There are about 1800 single-authored columns.
- The teaser text at the top of the columns contained 68 words on average (median: 66).
- The main part of the column is a little harder to count, because it also contains tables, figure captions and references. When I just count all words before the first appearance of “References” in the text, I get a mean of 1383 words (median: 1327). That seems well within the recommended range of 1000-1500 words.
- The most prolific writers have written up to 50 columns and the mean number of columns per author is 2.2 (median: 1).
Every column is assigned to one topic and several tags. I aggregated the 49 topics to one of 19 categories (e.g., I counted “EU institutions” and “EU policies” as “Europe” and “Microeconomic regulation” and “Competition policy” as “Industrial organisation”). This produces the following figure:
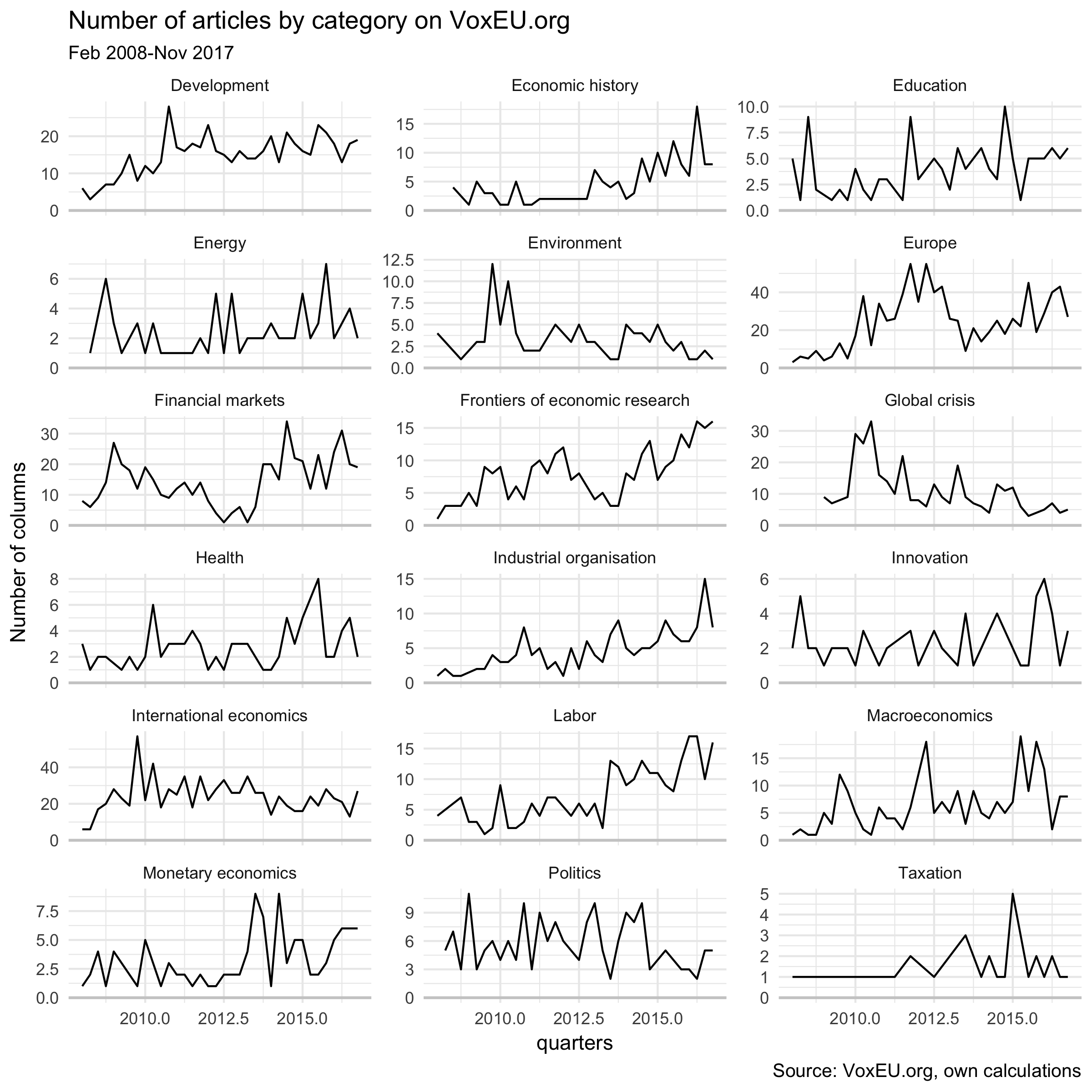
Some observations:
- The graph reflects the focus of voxeu.org. The top categories are “International economics” (950), “Europe” (930), “Development” (590), “Financial markets” (580).
- Microeconomic theory and econometrics are only rarely covered.
- The spike of the “Europe” category around 2012 might be related to the euro area sovereign debt crisis around that time.
- The topic “Frontiers of economic research” is a bit more vague.
- “Labor” and “Economic history” columns have become more important and columns with the topic “Global crisis” have become rarer.
Measuring complexity of text in columns
One fun exercise I’ve run is inspired by this blog post by Julia Silge. She explains how to use a “Simple Measure of Gobbledygook” (SMOG) by McLaughlin (1969) to find out which texts are hard to read. This works by counting the average length of syllables per words that people write. Words with fewer syllables are seen as easier to understand. The SMOG value is meant to show how many years of education somebody needs to understand a text.
I’m running this analysis separately on the columns teaser texts and their main body. Our own teaser text has 16 polysyllable words in four sentences and we calculate the SMOG value like this:
\[\text{SMOG} = 1.043 \cdot \sqrt{\left(16 \cdot \frac{30}{4}\right)} + 3.1291 \approx 14.6\]The rest of the column has 251 polysyllables in 65 sentences, which yields a SMOG of 14.4.
The winner of the VoxEU teaser text with the lowest SMOG count is this column by Jeffrey Frankel. It has a SMOG of 6.4, so taking the measure literally we would expect a kid fresh out of primary school to be able to understand it.
The column with the lowest SMOG value in its main column text is this column by James Andreoni and Laura Gee. It has 147 polysyllables spread out over 79 sentences, which yields a SMOG of 10.9.
I won’t name any offenders, but the highest SMOG score is 26.8. Understanding that text would require the substantial amount of education such as: 12 (school) + 3 (undergrad) + 1 (master) + 5 (PhD) + 6 (assistant professor) to understand.
The overall average SMOG value is 14.8 on teasers and 16.0 on main columns texts. So it seems that economists write on a level that college graduates can understand. SMOG doesn’t vary much by field, but it takes the highest value (on full columns) in “Industrial organisation” (16.9), “Monetary economics” (16.4) and lowest in “Economic History” (15.8) and “Global Crisis” (15.7).
The SMOG on the two column parts has a correlation of 0.27.
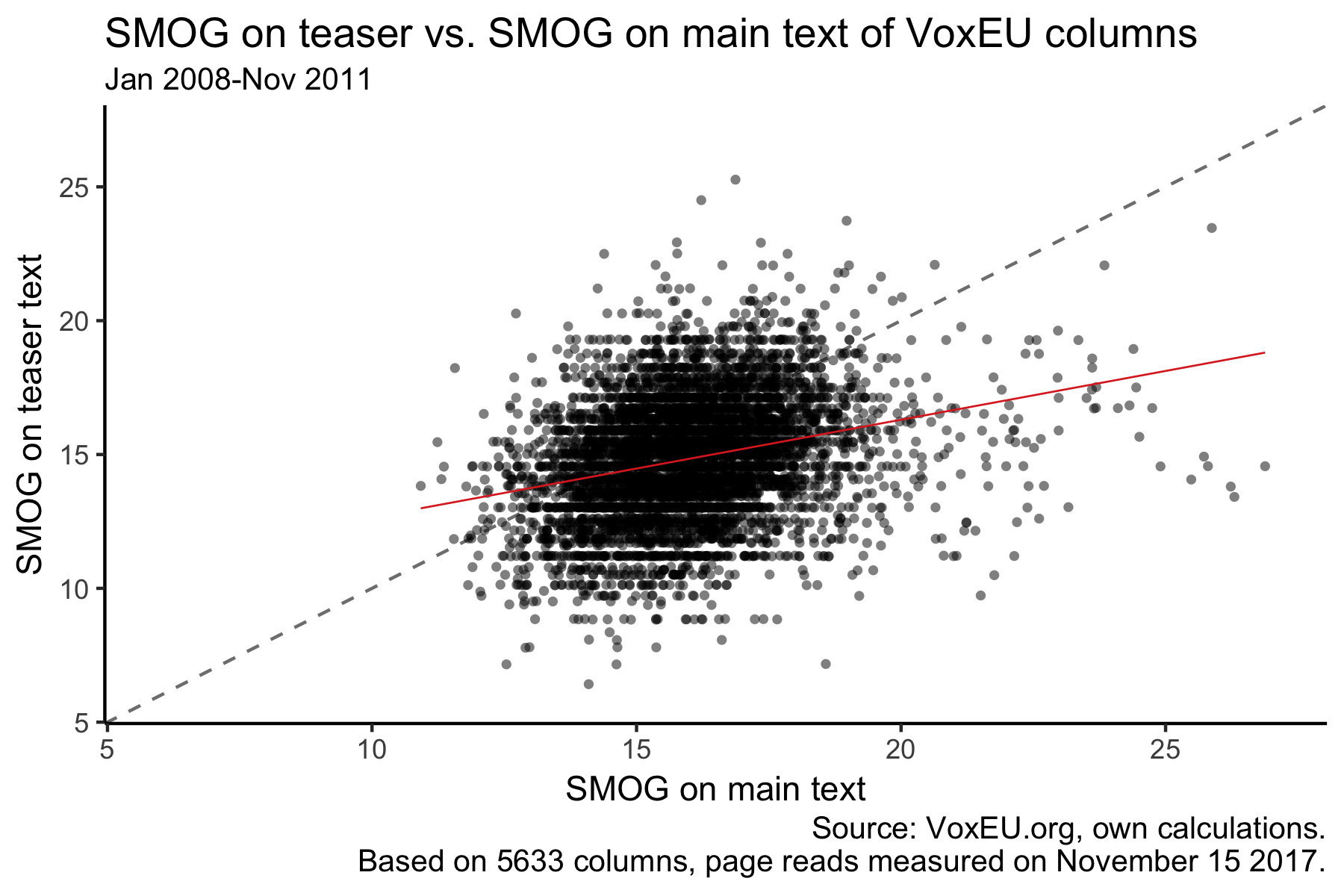
The OLS line is flatter than the 45 degree line which is probably a sign of the more accessible language in the teasers.
Interestingly, when we compare articles’ SMOG values with the number of times the page was read, we get the following negative relationship:
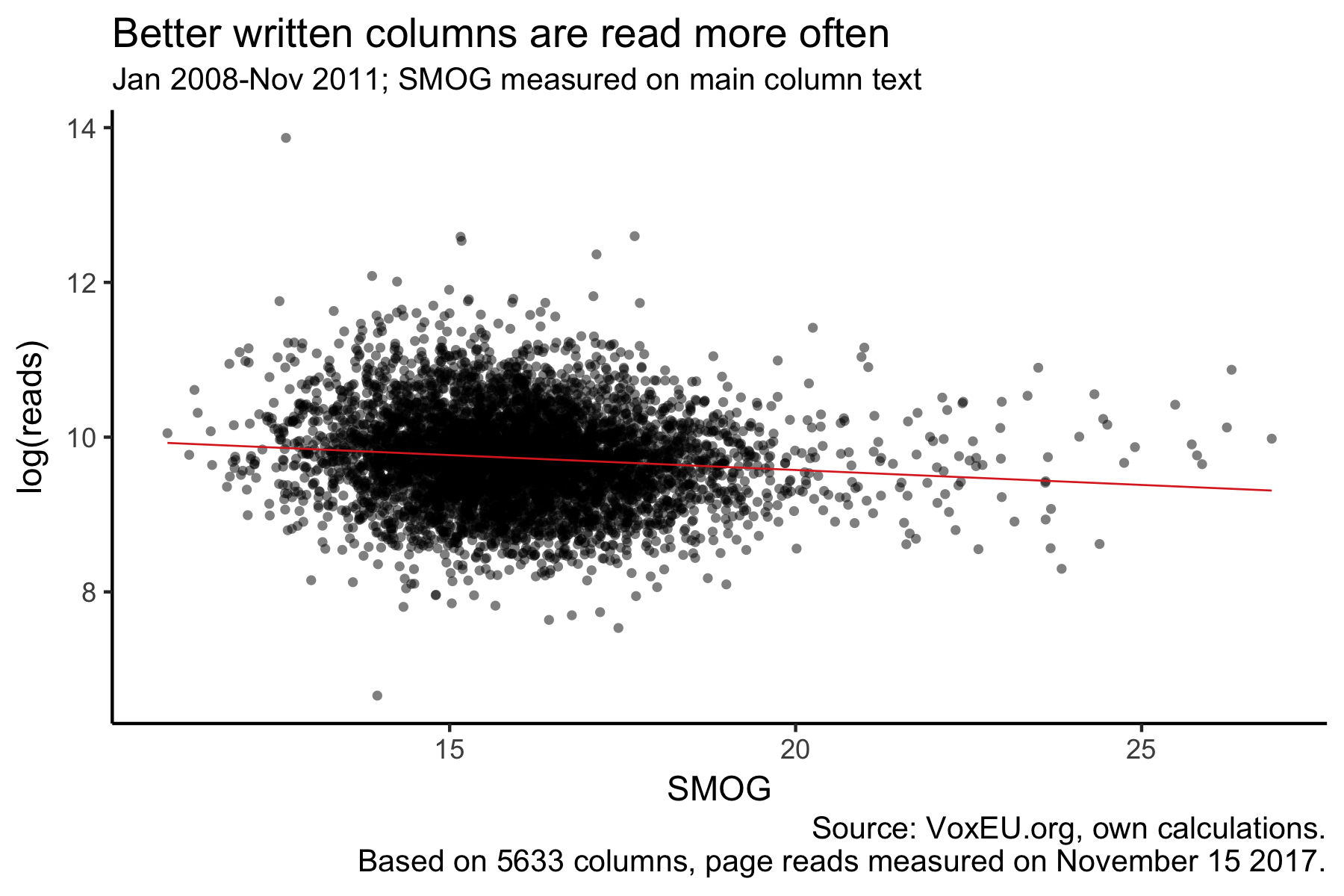
This also holds in a regression of log(page reads) on the SMOG values of both main text and teaser text, the number of authors, number of authors squared and dummies for the day of the week, quarter, year and – most importantly – the literature category (e.g. “Taxation”, “Financial markets” or “Innovation”). It’s not driven by outliers either and there is also a significantly negative relationship if I measure SMOG on the teasers only.
Writing columns that take an additional year of schooling to understand (SMOG + 1) is associated with 3 percent fewer page reads. Maybe that’s a reason to use fewer big words in our papers!
One explanation might be that more complex papers require the use of more big words. And that users on voxeu.org prefer clicking on articles that don’t sound too complicated. But better written papers might also just be inherently better in other dimensions. And because they’re more important, people read them more often.
References
McLaughlin, G. H. (1969). “SMOG Grading - a New Readability Formula”. Journal of Reading. 12(8): 639—646.