In a new working paper, Robert Shiller writes about the importance of narratives. He argues that economists should try to understand what the stories are that people tell each other and this influences decisions.
For a model of how such stories might spread, he refers to the Kermack and McKendrick SIR-model of disease infection. In the model, there are a fixed number of people \(N\) which are in one of three states: susceptiple (\(S\)), infected (\(I\)) or recovered (\(R\)). They evolve as follows:
\[\begin{eqnarray}
\frac{dS}{dt} =& -cSI \\
\frac{dI}{dt} =& \phantom{-} cSI - rI \\
\frac{dR}{dt} =& rI \phantom{a}
\end{eqnarray}\]
Initially, almost everybody is susceptible. Then more and more people become infected as susceptibles become affected when they meet an infective with a fixed probability (\(c\)). However, a fixed share (\(r\)) of the infected recover permanently every period.
In Julia, we could simulate the model as follows:
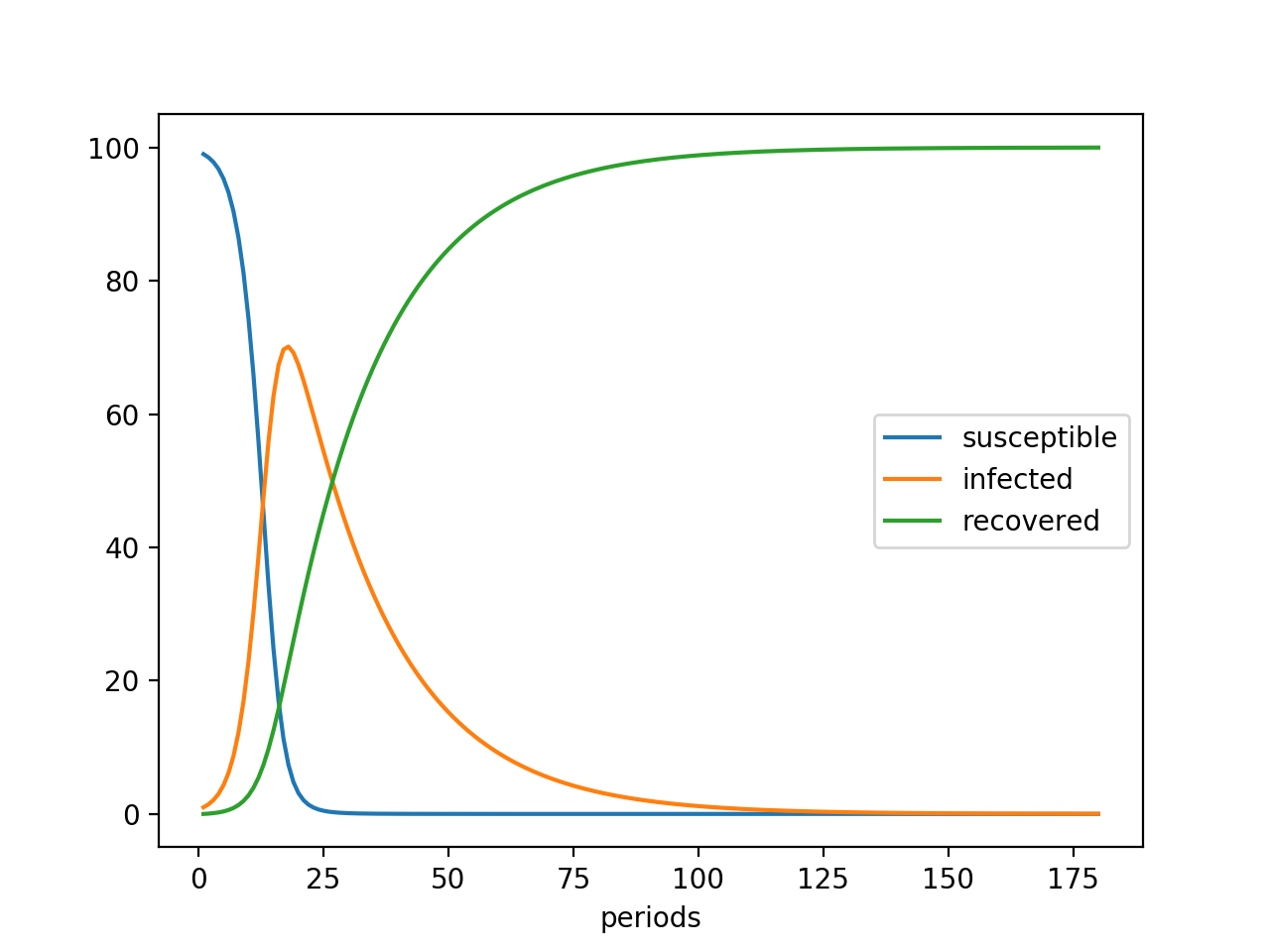
# ParametersN=100# population sizec=0.005# probability of infectionr=0.05# probability of recoveryT=180# periods# Initialize vectorsI=Float64[1]# initially infectedR=Float64[0]# initially recoveredS=Float64[99]# initially susceptible# Simulate modelfort=2:T# Next period's valuesRnew=R[t-1]+r*I[t-1]Inew=I[t-1]+c*S[t-1]*I[t-1]-r*I[t-1]Snew=N-Inew-Rnew# Save new value in vectorpush!(I,Inew)push!(R,Rnew)push!(S,Snew)end
Which gives:
The share of infected people peaks when there’s a large number of infected people around, but also a large enough share of people who have not yet had the disease. After that, slowly everybody gets infected, then recovers and the disease dies out.
I like this from Shiller’s paper:
Bartholomew (1982) argued that when variations of the Kermack-McKendrick model are applied to the spread of ideas, we should not assume that ceasing to infect others and forgetting are the same thing. Human behavior might be influenced by an old idea not talked about much but still remembered. This has been called “behavioral residue” (Berger, 2013).
The book “Coffee and Power” by Jeffery Paige has been regularly praised by Chris Blattman (here, here and here), so I thought it might be worth a read and I’ve not been disappointed. And it has one of the best book titles I know.1
In his book, Paige describes how an agro and agro-industrial elite took hold of most of the Central American countries in the second half of the 19th century. Their riches were based mainly on coffee, so hence the title.
After World War II, cotton, cows and sugar became more important. These were more capital intensive and gave more power to the agro-industrial part of the elite which were more friendly towards democracy:
The coffee export economy created the oligarchic political structures of Central America; cotton and cattle destroyed them. (p31)
Paige explains the tension between the conservative coffee growers and more progressive coffee processors. In the uprisings in the 1930s these elites held together, but in the 1980s they did not. What makes the experiences of these countries (El Salvador, Costa Rica and Nicaragua) interesting is that they started out from similar initial conditions, then diverged economically and politically and converged again on a similar path.
After a period of revolutionary turmoil, the three societies seem to be converging on a common model of electoral democracy and neo-liberal economic policy, but they took very different routes to arrive there.
The divergence in the political system of these three countries was even more striking given their underlying similarities.
[...]
The choice of El Salvador, Costa Rica, and Nicaragua for this study maximizes the divergence in political outcomes while minimizing the underlying variability among the cases. (p6)
Sociologists use a different vocabulary from that used by economists. Some examples:
Sociology
Economics
subordinate classes
workers
revolution
institutional change
neo-liberal
market-based
world capitalism
globalisation
positivist
positive/optimistic
commercial and military empire
powerful state
class/labor relations
wage bargaining, IO, ?
The author identifies the narratives people told themselves on what was happening and why.
They [the elite] made sense of the 1980s crisis by telling themselves and me stories about themselves, their families, their enemies, their countries, and their histories – their pasts, their presents, and their futures. (p48)
And people shared their stories very willingly:
Although my intention was to conduct an open-ended but structured interview, it soon became evident that most of those interviewed had a message they wanted me to hear and managed to tell it no matter what the specific questions. For the most part, these stories were told with considerable feeling and urgency. Sometimes they became almost confessional. […]. In the end [my different views] seemed to matter less than a willingness to take seriously what they had to say. (p50)
But amid Berlin’s great museums, legendary bondage clubs, and tormented geopolitics, [David] Bowie found what he needed: new ideas, new constraints, and new challenges.
Alex Tabarrok walks through a new political science paper that shows how the Chinese government sponsors social media post to “Distract Rather than Debate” (recommended):
As if this weren’t enough, an early version of KPR’s paper leaked and when the Chinese government responded, KPR became part of the story that they had meant to observe. The government’s response is now in turn used in this paper to verify some of KPR’s arguments. Very meta.
A whole lot of [economics] is about technocracy. […] Legendary economist Hal Varian summed it up when he said that “economics is a policy science.”
What use at all is a policy science when the people who make policy don’t listen to the science?
[...]
So plenty of economists must be asking themselves: If no one with power is listening, what’s the use of writing papers?
[...]
By shifting their focus to state and local government, economists who study policy issues can ensure their continued relevance during the long winter of Trump’s populist reign.
The author George R. R. Martin is best known for his “A Song of Ice and Fire” (ASOIAF) series. For those of you waiting like me for the next installment in the series, I recommend reading his other stories, especially Martin’s short story “The Sandkings” and his novel “Fevre Dream”.
(Warning: Spoilers ahead.)
On his website, Martin writes that people – when starting to write – should begin with short stories:
These days, I meet far too many young writers who try to start off with a novel right off, or a trilogy, or even a nine-book series. That’s like starting in at rock climbing by tackling Mt. Everest. Short stories help you learn your craft.
In ASOIAF, every chapter is complete in itself. The chapters start gently with often somebody approaching a castle or rowing over to an island. Then the person meets someone at the destination, the story builds up and some new information or some twist is revealed at the end of the chapter.
We recognize his style in Sandkings. Martin puts us in an imaginary world and introduces its elements on the fly. We learn about Kress who lives alone in his house with his pets, but then we suddenly get this sentence which tells us that this world is not like ours:
The next day he flew his skimmer to Asgard, a journey of some two hundred kilometers. (“The Sandkings”)
This story alludes to the motifs of sin and punishment and keeps you thinking after you’ve finished.
“Fevre Dream” reminded me of “Heart of Darkness”. We’re in 1852 and the experienced river-boat captain Abner March strikes a Faustian bargain with odd stranger Joshua York: The elegant other will provide the funds for a shiny new boat that will outrun all other boats – even the arch-rival Eclipse – but in return March must ignore the oddities and eccentricities of York and his companions. As the boat cruises down the Mississippi, signs accumulate that something is wrong. One of York’s friends squashes a Mosquito, stares at a the blood and then licks away the blood. York insists of stopping at places for no economic reason; places where people had been disappearing for a while.
And as the sun went down, the muddy water took on a reddish tinge, a tinge that grew and spread and darkened until it seemed as if the Fevre Dream moved upon a flowing river of blood. Then the sun vanished behind the trees and the clouds, and slowly the blood darkened, going brown as blood does when it dries, and finally black, dead black, black as the grave. Marsh watched the last crimson eddies vanish. No stars came out that night. He went down to supper with blood on his mind. (“Fevre Dream”)
The plot line of Fevre Dream is pleasantly unpredictable. We see many of the motifs in this story that we find again in ASOIAF: unfulfilled longings, long time jumps, the undead, blood, the contrast of life and death and night and day. Even some phrases are familiar: “blood of my blood” and (almost like Melisandre) “The nights are full of blood and terror”; and at another place “The night is dark, the day is long”.
Let me know if you’ve read any other George R. R. Martin stories and can recommend any.
Most job tasks, most activities, involve a panoply of skills. Brains and brawn. Technical expertise and expert judgment. Or “perspiration and inspiration”, in the words of Mark Twain. In general, all of these tasks need to be done to accomplish the work. So eliminating one set of them doesn’t mean there’s nothing left to do and in economic terms, automating a subset of the tasks increases the economic value of what’s remaining. It complements those workers. (link)
He also ventures into the marriage market, unequal child investment (the Trump family gets a laugh) and even artificial intelligence and the technological singularity.
Fundamentally, when we’re concerned about automation we’re talking about a concern about rising productivity, right? We’re not talking about shielding ourselves from a bomb that’s falling onto our city. The bomb is exploding productivity. It’s that we’re actually being able to do more and more with less. That may create a distributional problem, as I’ve highlighted in this talk. But it doesn’t create a wealth problem. It means we have lots and lots of wealth. (link)
A discussion on the Fred Blog of “Price growth at the tails” (recommended); do check out the second plot. Here:
[T]o make the inflation rate meaningful, we must condense this distribution of prices to a measure of, as statisticians would call it, “central tendency.” However, reasonable people can differ on the proper measure because the distribution of price changes has long “tails.”
[...]
Within this basket, the distribution of price changes is usually approximately symmetric, […]. The interesting exception is during the Great Recession period, when commodity prices fell sharply, bringing a strong negative skewness for the first time since the mid-1980s. […] In this period when the economy seemed to be in tremendous flux, the headline, average CPI moved little. However, the skewness—and the tails of the price distribution—changed quite a bit.
Why don’t easy to use, helpful online banking accounts like the one described here exist?
Suppose you could design the interface for your own investing software. […] What would you put on that first landing page?
For mine, I’d intentionally not show most of what shows up on DIY brokerage sites today:
The shares/price/value of each position I hold
Whether those positions are in a gain or a loss
The historical performance
Market news related to my holdings
These aren’t just useless for making forward-looking decisions – they’re actively harmful.
New UBS Public Paper by Dominic Rohner (download pdf) on conflicts and institutions.
On giving up your native language by Yiyun Li in the New Yorker: “To Speak is to Blunder”:
Over the years, my brain has banished Chinese. I dream in English. I talk to myself in English. And memories—not only those about America but also those about China; not only those carried with me but also those archived with the wish to forget—are sorted in English.
29% of German economists think Italy should exit the eurozone (in German).
In Germany, the book the “Knigge” describes the etiquette that the upper-class ought to follow. The first version was published by the nobleman Adolph Freiherr Knigge in 1788 as “Über den Umgang mit den Menschen” (roughly “How to interact with people”). Many updated Knigges have since been published and they reflect the values of their times. I read the version by Kurt von Weißenfeld “Der moderne Knigge” from 1950:
I liked the part on children: Children who’re kept busy with good activities are well-behaved children. Sensible ways to engage children must be taylored to their abilities and interests (“Interessenwelt”). (p19)
Don’t take your issues out on your children. (p20)
On relationships, a sentence that might have come from Esther Perel: Where there is closeness, there is soon tightness. (p29)
A surprising amount of text is devoted to how a wife should treat a husband who comes home in a bad mood. Apparently, wife who doesn’t remain silent when the husband is in a bad mood is a “dumb goose” (p30). The supposedly correct response is for the wife to go to another room and leave cigarettes and cognac with him (p31).
One of a wife’s duties is to install “half a dozen” ash trays in every room and empty them twice a day. She should also fake enjoying her husbands hobbies, such as playing cards.
And then there’s this:
“Everybody considers Mrs Else enchanting”
“But enchanting she is only for others. At home she doesn’t even bother to put on a dress or make her hair. Such a “grabby” woman easily repels her husband, just as a too dashing man repels a woman.
To top it all off, Weißenfeld delves into the 1788 Knigge’s treatment of women and how society has progressed and is now “egalitarian”.

 “Everybody considers Mrs Else enchanting”
“Everybody considers Mrs Else enchanting” “But enchanting she is only for others. At home she doesn’t even bother to put on a dress or make her hair. Such a “grabby” woman easily repels her husband, just as a too dashing man repels a woman.
“But enchanting she is only for others. At home she doesn’t even bother to put on a dress or make her hair. Such a “grabby” woman easily repels her husband, just as a too dashing man repels a woman.