I guess in the end, we need a certain fatalism. There are many ways we can try to adapt our estimates, but as Angus Deaton writes, the further two countries are away in time or structure (say Germany vs. Switzerland or Thailand vs. Kenya) the harder it becomes to compare the two in terms of production and prices in any meaningful way. It does not mean that we should stop trying to do better, but some fundamental gaps might simply not be bridged.
Scientific code should be held to higher standards than other software. So it would help to write test cases that check if the outputs of our programs look plausible. But for some people, that’s not enough.
Yaron Minsky, who introduced the exotic programming language OCaml at the financial trading firm Jane Street, explains how they go about writing their sensitive systems:
We do an enormous amount of trading. There’s billions of dollars of nominal value kind of sloshing back and forth in the systems that we build. And what this means is, we are very nervous about technological risk. Because there is no faster way to light yourself on fire than to write a piece of software that makes the same bad decision over and over in a tight loop. (link)
He argues that on such a scale normal software testing isn’t enough, because even the very unlikely strange cases – that you haven’t thought about and written test cases for – might plausibly happen. So you have to understand the code really well and to make it readable, so that other people can check its correct functioning.
The story of GDP since 1940 is also the story of macroeconomics. (p20)
This is by Diane Coyle in her book “GDP: A Brief but Affectionate History”. Ever since the first Gross National Product (GNP) accounts were published for the United States in 1942, a great range of assumptions on what to include were necessary: Should we count services, the public sector or the financial sector? Ultimately these accounts are a social construct, so we need to decide which activities are worthwhile.
In macroeconomics, researchers have tried to get away from the model of the representative household by introducing heterogeneity among households. And similarly to these theoretical developments, new ideas for national accounts have been put forth: Thomas Piketty, Emmanuel Saez and Gabriel Zucman propose (pdf) to start using “distributional national accounts”. Previously we could answer what the aggregate economy produces and consumes, but these new accounts promise to tell us: How much has income grown for somebody at a particular place in the income distribution?
There already exist some indicators for this question, such as the top 1% income share estimated from tax returns. But what’s new is to provide accounts that are consistent with the macro data.
It’s interesting to ponder over the question of how to convert nominal to real values for income groups. Should we use one inflation rate for everyone or a different inflation rate for every income bracket?
Richer people spend less on food and other items relatively to their total income than do poorer people. The German statistical office, for example, offers this tool (in German) to calculate personalized inflation rates. But there are good reasons for and against using a single inflation rate and our choice should depend on how we want to think about income:
Income as consumption. More income means you can buy and consume more goods now or in the future. Normally, this is what economists think of when they hear “income”.
Income as economic power. Being rich also comes with more influence, so income might be a good indicator for who’s powerful in society.
The first concept is probably better suited for international or intra-temporal comparisons. We might ask: “How much better off is somebody in Switzerland relative to somebody in Kenya?” or “How much better off is somebody in Germany now than compared to 1950?” And for both questions we probably want to take into account that prices differ in the two countries and have been different in the past.
But within a single country at one point in time, the second concept is likely more useful. If both rich and poor people generally live nearby, compete for the same resources and participate through the same political entity, then we should probably use the same price indicator for both groups.
So it seems to make sense to just use one inflation rate in the distributional national accounts. But how large is the dispersion in prices that people actually pay?
Greg Kaplan and Sam Schulhofer-Wohl (pdf) look at scanner data for the prices of sales transactions by households [source:MR]. They find great variation among the prices that people pay for similar goods and this effect even dominates the movements of the aggregate price level:
[…] almost all of the variability in a household’s inflation rate over time comes from variability in household-level prices relative to average prices for the same goods, not from variability in the aggregate inflation rate.
And even similar households pay different prices for the same goods:
Households with low incomes, more household members, or older household heads experience higher inflation on average, […], but these effects are small relative to the variance of the distribution, and observable household characteristics have little power overall to predict household inflation rates.
So something else, apart from income, dominates individual inflation rates.
This is based on 500 mio. transactions by 50,000 U.S. households between 2004 and 2013. Coyle also argues in her book for using “user-generated statistics” (p138) to improve our understanding of economic activity. But it’s a pity that the time dimension for this kind of data is relatively short.
It’s previously been found that relevant economic actors (managers of firms in New Zealand) know remarkably little about the aggregate inflation rate. Kaplan and Schulhofer-Wohl offer the intriguing explanation that the aggregate inflation rate might simply matter little to individuals as they face different prices anyway. This probably also holds implications about how central banks should think about the transmission of monetary policy.
However, Kaplan and Schulhofer-Wohl say it’s important to know whether people can forecast their own personal inflation rate. If they cannot, then people might keep looking at the aggregate inflation rate as the best predictor of where also their personal price level will be in the future.
Coyle argues in her book that though GDP has many imperfections, it’s still the best way to measure economic activity and that instead replacing it we should use a “dashboard of indicators” (p118):
The U.S. Commerce Department called GDP one of the greatest inventions of the twentieth century, and so it was. There is no replacement for it on the horizon. (p138)
Not a replacement, but the authors Piketty, Saez and Zucman have a good point that we should add the cross-sectional dimension to it. So let’s hope that statistical agencies will take over this task, through maintaining and publishing these distributional national accounts.
That’s hard to answer, but we know that private credit tends to increase before the trouble starts. But why do people take on so much debt in the first place? Is it because of wrong-headed regulation or do people become too confident – for other reasons – about how much they will be able to repay in the future?
Pedro Bordalo, Nicola Gennaioli and Andrei Shleifer propose a model in which households over-interpret streaks of good or bad news and extrapolate these into the future. They show that these psychological swings can help explain credit cycles and might be a source of economic fluctuations.
In the model, states of the world are represented by a random variable \(\Omega_t\). The realizations \(\omega_t\) determine the share of firms that will be productive – and repay their debts – in period \(t\).
The representative household saves by lending to firms and takes into account the probability that some firms will not repay. However, the authors distort the household’s expectation with a psychological bias they refer to as the representativeness heuristic. People tend to take properties that are more likely in one class than another to represent that class. So red hair is representative for the class “Irish”, even when dark hair is much more common in Ireland.
Agents take the change of their expectation of the future state as a sign for things to come. Biased agents judge the representativeness of state \(\omega_{t+1}\) by comparing the true conditional distribution of the future state \(\omega_{t+1}\) with the probability that a rational agent assigned to that state before the information on the current state \(\omega_{t}\) has become available. The authors refer to this way of forming expectations as diagnostic expectations.
If the state of the economy is better than expected, then expectations about future states are revised upwards by more than what is justified by rational expectations. Households become too optimistic about firms’ ability to repay their debts and are happy to lend more. This reduces the interest rate and lets firms invest more. This leads to more production and thus an economic expansion. The effect works vice versa for bad news which makes the household overly pessimistic:
When times are good, households are optimistic about the future state of the economy. The perceived creditworthiness of firms is high, households supply more capital, the interest rate falls, firms issue more debt and invest more, and future output rises. When times turn sour, households cut lending, firms issue less debt and cut investment, and the economy contracts.
They don’t mention welfare, but households are obviously worse off than if they would accurately form expectations.
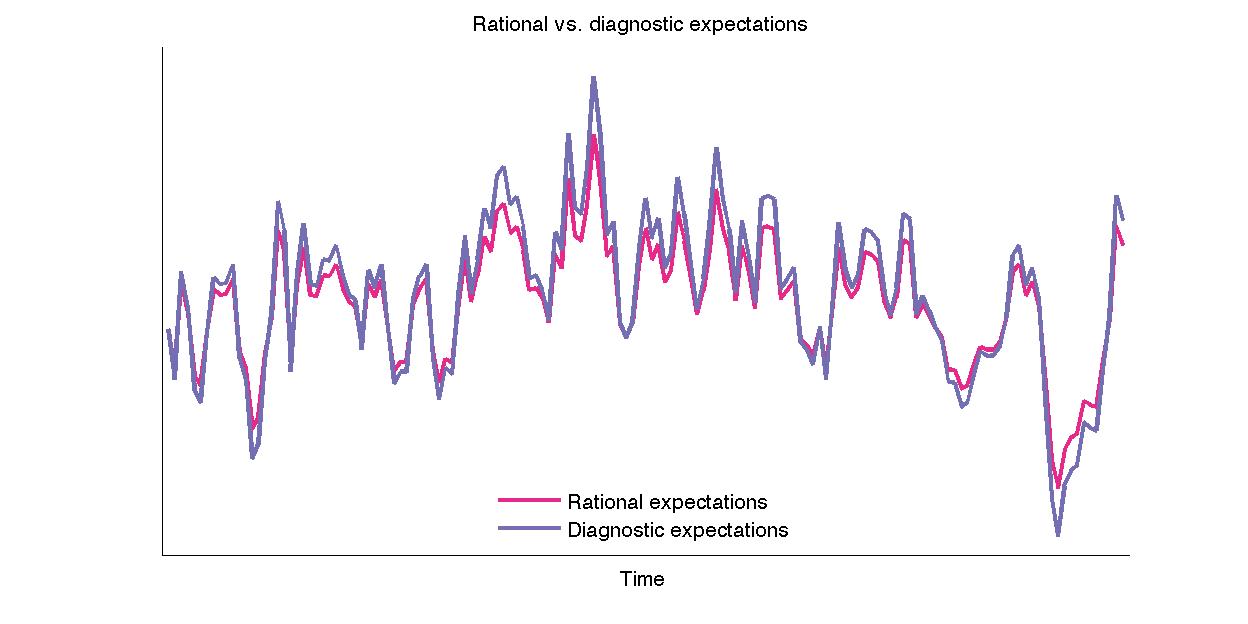
When we assume \(\omega_t\) to follow an autoregressive process we can draw a series and simulate how rational expectations compare with diagnostic expectations:1
Diagnostic expectations overshoot, so they are larger than rational expectations when times are good and below them when times are bad.
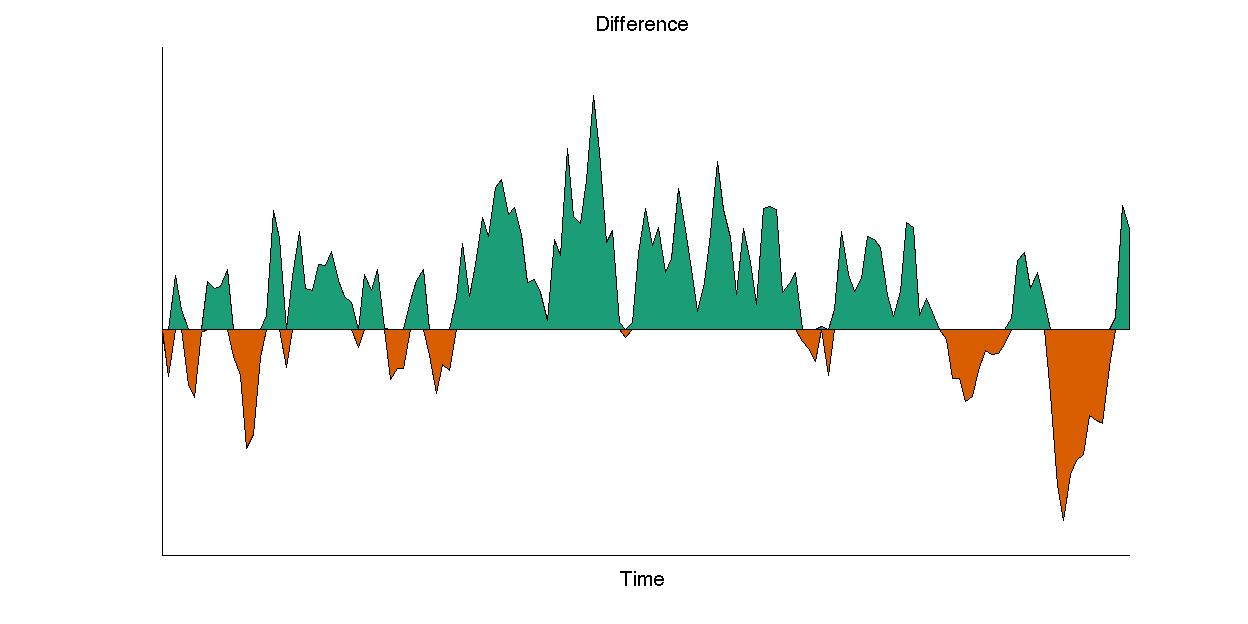
When we plot the difference between the two expectations we get:
Where we can clearly see the psychological boom periods (green) and bust periods (orange).
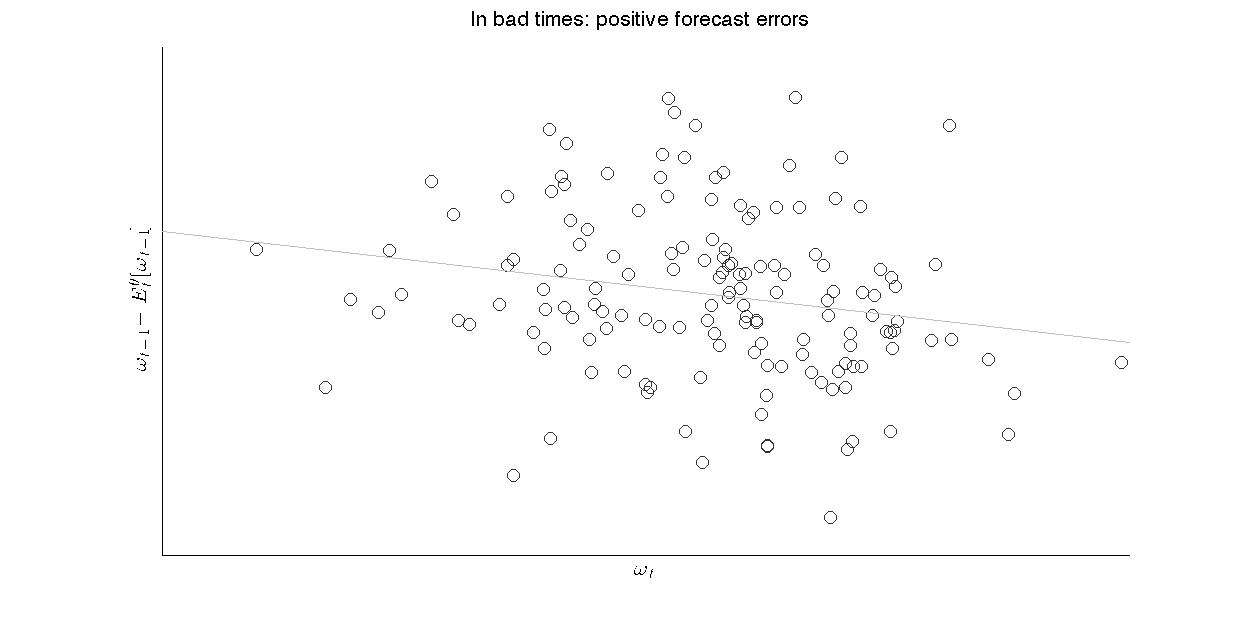
In bad times, households are too pessimistic, so we can expect positive surprises. The same holds in good times: The households expects things to be good again, so he is too optimistic. This results in a negative correlation of forecasts errors with the current state:
In total, this results in:
endogenous credit cycles and
larger macroeconomic volatility.
However, the signals that different people in the economy get have to be sufficiently correlated for this to matter in the aggregate. Is that realistic? If there is even a bit of heterogeneous uncertainty about which state \(\omega_t\) the world is currently in, then some households might become optimistic and some pessimistic. Could this not lead to some averaging out of these effects?
Also what’s the policy implication here? Do maybe professional forecasters or central banks not make these mistakes and should they therefore inform or regulate the decision-making of households? Because we would actually much prefer if people did not form their beliefs like that. Robert Shiller writes this in his book:
We must consider how to deal with the change in thinking that leads people to think we have entered a new enlightenment, changes that, through their effect on market prices, impinge on all our lives.
We have to consider what we as individuals and as a society should be doing to offset some of the ill effects of this exuberance. (p203, “Irrational Exuberance”)
But he ends on:
Ultimately, in a free society, we cannot protect people from all the consequences of their own errors. (p230, “Irrational Exuberance”)
Also, must we assume that all people form their expectations like this? What if there are some clever investors that don’t have overshooting expectations? They might arbitrage the mispricing in firms’ bond prices away, right?
And who might those arbitrageurs be? People like Cliff Asness:
ASNESS: Second reason is a behavioral story. Someone out there is making a mistake. I gave you two. Underreaction and overreaction are both the behavioral story. They’re both somebody out there making an error, doesn’t mean markets are terrible by any means. I’m a big believer in markets but at the margin, they’re making an error and you take advantage of it.
[…]
COWEN: Let me give you my intuition in favor of why it might be overreaction and you tell me what you think.
You receive a signal about the world. It’s to some extent a private signal and you over-interpret that signal and you think it’s a signal about the whole world so you overreact. That leads to some price movement, which is propagated through time. But, at least some people think, past that 12-month time window, momentum ceases, and there’s even a bit of price reversal.
Eventually, you learn that you’ve been overreacting by thinking your private information is more general, more systematic than it is and then things snap back a bit. Does that psychological hypothesis explain this mix of price reversal in the longer term and momentum in the shorter term? Do you think that makes sense or not?
[…]
ASNESS: Let me take this another way. I think we are mixing overconfidence with overreaction a little bit. New news, people might be overconfident in how much they understand it, but they don’t seem to incorporate it enough.
Yes, there exist limits to arbitrage for various reasons, but it would be nice if we didn’t have to assume these for the real effects of diagnostic expectations to go through.
I like how the authors relate their mechanism to the literature on “financial shocks”:
When the economy is hit by a series of good news, investors holding diagnostic expectations become excessively optimistic, fueling as in the current model excessive credit expansion. During such a credit expansion households would pay insufficient attention to the possibility of a bust. As fundamentals stabilize, the initial excess optimism unwinds, bringing this possibility to investors’ minds. The economy would appear to be hit by a “financial shock”: a sudden, seemingly unjustified, increase in credit spreads. Agents would appear to have magically become more risk averse: they now take into account the crash risk they previously neglected.
And this bit:
Perhaps as important an advantage of our approach is that expectations are not delinked from news, but rather follow a distorted true process of the data, what we have referred to as the “kernel of truth” hypothesis.
To conclude, the paper provides a theoretical explanation how overshooting expectations due to the representativeness heuristic can cause financial and macroeconomic cycles.
I reviewed the book here, but skipped MacAskill’s section on how to choose a career, because it got a bit lengthy already.
His career advice is unusual:
Taken literally, however, the idea of following your passion is terrible advice. Finding a career that’s the right “fit” for you is crucial to finding a career, but believing you must find some preordained “passion” and then pursue jobs that match it is all wrong. […] First, and most simply, most people don’t have passions that fit the world of work. […] Second, your interests change. […] This takes us to our third point against passion, which is that the best predictors of job satisfaction are features of the job itself, rather than facts about personal passion.
I think you don’t actually have to optimize for altruistism to find the following good advice:
This means it’s best to take an empirical approach, trying out different types of work and using your track record to predict how well you’ll perform in the future. At the start of your career, be open-minded about where you’ll eventually be able to perform best.
Exploration value provides a reason in favor of working in the for-profit sector for a year or two: you might discover that the opportunities there suit you well. People embarking on their careers often neglect these considerations. People often tend to think of choosing a career as an all-or-nothing proposition: a one-off life decision that you make at age twenty-one and that you can’t change later. A way to combat this mistake is to think of career decisions like an entrepreneur would think about starting a company.
I think he takes his advocacy of thinking through the long-run and general equilibrium effects of one’s career choice a bit to far, though. He discusses the choice of a PPE student at Oxford who’s deciding if she should enter politics. But the amount of assumptions and simplifications that go into that analysis make me doubtful if much is learned and reminds of me fermitizing.
MacAskill has taken this focus on career guidance further with his organization 80,000hours. Among other things they publish career reviews. (Luckily they have a positive take on economics PhDs).
In Gregory David Robert’s novel “Shantaram”, the protagonist Lin comes to India from Australia and is overwhelmed (emphasis added):
Now, long years and many journeys after that first ride on a crowded rural train, I know that the scrambled fighting and courteous deference were both expressions of the one philosophy: the doctrine of necessity. The amount of force and violence necessary to board the train, for example, was no less and no more than the amount of politeness and consideration necessary to ensure that the cramped journey was as pleasant as possible afterwards. What is necessary! That was the unspoken but implied and unavoidable question everywhere in India. When I understood that, a great many of the characteristically perplexing aspects of public life became comprehensible: from the acceptance of sprawling slums by city authorities, to the freedom that cows had to roam at random in the midst of traffic; from the toleration of beggars on the streets, to the concatenate complexity of the bureaucracies; and from the gorgeous, unashamed escapism of Bollywood movies, to the accommodation of hundreds of thousands of refugees from Tibet, Iran, Afghanistan, Africa, and Bangladesh, in a country that was already too crowded with sorrows and needs of its own. The real hypocrisy, I came to realise, was in the eyes and minds and criticisms of those who came from lands of plenty, where noone had to fight for a seat on a train.
This reminds me of people from rich countries talking about the smiling people you they in “mud villages” and how that must mean that development aid is unneccessary or harmful. No, a higher degree of social harmony is just what is necessary.
I really like Paul Theroux’s travel writing. But his views on development: not so much.
He seems to hold odd views on why some countries are poor and I find his take on foreign aid one-sided. (Anne Lowrey and Chris Blattman concur.)
In the same talk I wrote about before, Theroux also says:
Where are we going? You think – when you see development, you think: “Do places just keep developing and developing and developing and developing?” And it’s straight north and they just keep developing until they become a utopia? Or do things fall apart? I tend to think, if you’ve lived a certain length of time, you say: Eventually things fall apart. It’s not straight north. (link)
Traveling in the south, in the southern USA, there are some roads in the south that were once main roads. […] So they had restaurants, hotels, motels, petrol stations. Highly developed roads. Two-lane highways. […] Now, if you go down there, it looks like doomsday. The restaurants are all closed, the motels are all closed, the petrol stations are closed. There are just a couple of little shops. […] What happened was a different road was build. […] And the towns died. (link)
He does not seem to see benefits from trade and his world is zero-sum: One part can only benefit if the other part is worse off. It’s surprising to me, given how much he has clearly benefited from globalization through being able to safely travel all over the world, living and teaching in Singapore and having a global English-speaking audience that reads his books.
In a different, recent, interview he talks about Chelsea Clinton being called a “humanitarian”:
It’s a pretty good gig, actually, being a humanitarian if your family – I mean you’re that age and you’re a humanitarian. I would say, you know, join the peace corps, spend two years in a village, then you can be – that’s the apprenticeship for a humanitarian. She’s married to a multi-millionaire and lives in a million dollar apartment in New York City. […] It’s telescopic philanthropy. (link)
Theroux: The long march of the common man and woman is my mission, actually.
(Applause)
Iyer: Of course the guy who won the Nobel Prize for economics yesterday has a blistering attack on foreign aid.
Theroux: Angus Deaton, that’s right. […] He’s written the definitive book, why aid is harmful. (link)
He argues that the population increase has made people worse off:
In 1950, the population of the United States was 150 million. […] Now it’s 350 million of the United States. There are 7.5 billion people on the planet. Man is an invasive species. Of course the world is getting worse. It’s getting much worse and will continue get worse. (link)
He provides a couple of stories of how you cannot safely cross Africa nowadays and you cannot cross borders easily in the easter Mediterranean. Is that convincing evidence of anything? Many parts of the world are safer now (such as Southeast Asia).
And actually, Angus Deaton spends the first half of his book showing how much better the world has become for many of its inhabitants. A bit of perspective could be obtained here by reading Pinker or browsing Our World in Data.
It’s irritating how critical Theroux can be of people who don’t read novels, but then is so unaware his lack of expertise to pass judgement on a topic like this. And that matters because he’s rightly famous for his books, so people might infer that he also speaks with authority on the subject of how to raise people out of poverty. But he does not.
In the end, a commenter asks him about the critique of his New York Times piece. Theroux answers that he thinks that some of the letters were quite reasonable and he cites Deaton again:
This is what Angus Deaton, whom we alluded to earlier - you can’t determine poverty by the per capita income. You should do it in terms of self-sufficiency. A “poor” person in Africa may live in a mud hut, but a mud hut is preferable to a cement house in many places. A thatch roof is more effective than a tin roof in many places. […] You look at mud village and you say, “Gosh, it’s a mud village.” People are living there as they’ve lived there for many years and they sustain life in a viable way. They may not have education, they may not have a cell phone, but they can feed themselves in a way that people can’t in other places. Urban Africa is different. […] But I don’t think that because someone is earning a dollar a day that necessarily they are poor in the same way that someone in Hollandale, Mississippi, is poor. The person in Hollandale, Mississippi, doesn’t have a garden. They are living precariously. They once had a job. […] The people who wrote, “There are poor in China”. I don’t see the correlation. I think the poor in America are comparable to the poor anywhere in the world. (link)
He probably does have a point that the people one meets in poor countries often seem quite happy. But I don’t agree with his view on “self-sufficiency”. People in “mud villages” might well prefer to buy their food in a supermarket and be educated or have a smartphone. It’s our perspective of being able to have these things that we can look back and romanticize how nice it must be without them.
Also, looking happy is not the same as living good lives. If you sit in the tube in London, many people will look stressed and unhappy. But that’s just because they can. They don’t have to look happy all the time and they’ll reserve that for the friends they’re about to meet or their children they’ll pick up from school. In developing countries there’s a greater need for constant social harmony.
Maybe his views are even an explanation for the rise of Donald Trump and Bernie Sanders. If even a cosmopolitan, educated, wealthy liberal is against trade, then I think we’re in for a globalization backlash:
The piece is really about: The contradiction of people who become billionaires by outsourcing. So there’s a factory in Arkansas, Mississippi, making furniture or shoes. And they say, “You know, what we want is, we want bigger profits”. So they move the shoe factory to Vietnam. Then they become billionaires. Then they say: “We want to lift people out of poverty.” […] It’s shameful. (link)
{kind=link}