Should central banks change the money supply to try to deflate bubbles in asset markets, such as the markets for bonds or houses?
Loretta Mester, the president of the Cleveland Fed, says “No”, because:
the central bank should focus on price stability and employment and
there are other tools for improving the financial system.
This reminds me of the debate about the impact of monetary policy on economic inequality. Does printing money make some people better or worse off? Obviously yes. In the extreme case, if the central bank caused high inflation, then people holding real assets like land, houses, factories or stocks (which adjust when firms raise prices and dividends) would benefit. But people holding nominal claims like bonds would suffer. But monetary policy that acts in smaller steps likely also has distributive effects through more subtle channels.
But I think the main reason to care about these effects is that they might change the transmission of monetary policy on the real economy. For everything else, such as questions of social fairness and the redistribution of income and wealth, we have a much better tool: taxes.
Jens Weidman, the president of the German Bundesbank, recently spoke about financial stability:
In hindsight, it looks as if, for a while, confidence had turned into complacency. But the financial crisis has reconnected everybody with the reality that the success of monetary policy depends on conditions it cannot create on its own. In particular, it is dependent on a stable financial system.
[…]
The crisis has reminded us that financial exuberance, too, is potentially a harbinger of unstable consumer prices.
And the following relates to the argument that monetary policy might not be the right tool to address financial stability (or inequality):
Tinbergen’s timeless insight continues to apply: to reach each policy goal reliably, at least one separate instrument is needed for each policy area. The crisis has therefore spawned a whole new set of instruments – macroprudential policies – designed to target specific sectors of the financial system.
Noah Smith debates wealth swings vs. debt as a catalysts during financial crises:
If wealth effects are the big culprit, then taming asset bubbles becomes the central task for recession prevention. If it’s debt that does it, the key is to stop households from borrowing so much.
Seveneves is a good read. It’s a nice follow-up to the The Martian, though a bit less “hard” and more “epic” science fiction. [source]
While North American PhDs tend to work with more than three different researchers within six years after graduation, PhDs of the German-speaking area work with barely a single collaborator. We find positive and significant correlation of the number of distinct coauthors with research quality.
Wir sind geprägt vom naturwissenschaftlichen Verständnis von Theorie als etwas Allgemeingültigem und machen uns zu wenig klar, dass Modelle nicht Theorien sind, sondern Sprachspiele zum logischen Verständnis von Zusammenhängen.
[…]
In den meisten Fällen reichen die Daten, die man bekommen kann, nicht für statistische Analysen aus.
[…]
Ob ich das jeweils “richtig” gemacht habe, weiß ich nicht. Aber das ist genau mein Punkt: Wir haben kein Rezept und kein professionelles Ritual dafür, wie man so etwas “richtig” macht. Wir haben oft noch nicht einmal das Bewusstsein, dass es da ein Problem gibt. Wir brauchen dieses Bewusstsein.
How should we act, if our goal is to do the most good we can?
William MacAskill, a recent PhD graduate in philosophy from Oxford, adresses this question in his book “Doing Good Better”. (His dissertation on the same topic can be found here.)
He advocates a rational approach to giving in which one reflects on how to help most effectively. He argues that altruism does not need to arise spontaneously from personal experiences:
We very often fail to think as carefully about helping others as we could, mistakenly believing that applying data and rationality to a charitable endeavor robs the act of virtue. (pos 246-7)
He also compares donating to investment and points out that:
One difference between investing in a company and donating to a charity is that the charity world often lacks appropriate feedback mechanisms. (pos 259-260)
Instead, he proposes a strategy he calls “Effective Altruism”:
Effective altruism is about asking, “How can I make the biggest difference I can?” and using evidence and careful reasoning to try to find an answer. (pos 270-272)
As the phrase suggests, effective altruism has two parts, and I want to be clear on what each part means. As I use the term, altruism simply means improving the lives of others. Many people believe that altruism should denote sacrifice, but if you can do good while maintaining a comfortable life for yourself, that’s a bonus, and I’m very happy to call that altruism. The second part is effectiveness, by which I mean doing the most good with whatever resources you have. (pos 274-278)
Many economists will find MacAskill’s thinking and his proposals quite natural. He explains how absurd some parts of charity giving are. You first decide how much to give and then choose who to give it to. With everything else, you would first compare the options and then consider how much each is worth to you.
In economics, we have trouble comparing utility across people. But sometimes we have to, as when deciding who to tax or if policies are worth it that make some people better and some people worse off. For this, MacAskill proposes to use “quality adjusted life years” (QALYs) to measure the impact of one’s charitable actions. QALYs sound to me a lot like the present value of life-time utility (though without discounting). The clever thing is to normalize it to the value of expected normal life quality which makes them comparable across people. And he’s honest about the inherent problems in comparing suffering across people:
However, there are many harder cases: If you can prevent the death of a five-year-old or a twenty-year-old, which should you do? (pos 507-508)
I read MacAskill as being quite optimistic about the change that any one person can bring about:
The difficulty of comparing different sorts of altruistic activity is therefore ultimately due to a lack of knowledge about what will happen as a result of that activity, or a lack of knowledge about how different activities translate into improvements to people’s lives. It’s not that different sorts of benefits are in principle incomparable. (pos 580-583)
He argues against giving to causes that one knows personally:
If I were to give to the Fistula Foundation rather than to the charities I thought were most effective, I would be privileging the needs of some people over others merely because I happened to know them. (pos 609-610)
Well, but people are exactly like that. It’s honorable if he isn’t, but for most people that’s probably a good rule of thumb to follow.
What matters is not who does good but whether good is done; and the measure of how much good you achieve is the difference between what happens as a result of your actions and what would have happened anyway. (pos 976-978)
Where I think MacAskill goes wrong is by not taking into account people’s preferences and limitations. It’s ok to have a weighting function about other people’s suffering. The suffering of people close to you is probably more important to you than to that of a person in the next town or a person on another continent.
I also don’t think that he can explain why people act altruistically through expected utility. He writes that the reason people go to vote is not because they expect their vote to matter, but because you weigh everybody else’s benefits as well and decide that the potential costs and benefits are huge.
I disagree.
He cites Steven Levitt as saying that people vote because it’s fun and their wife will love them more for it. I don’t think so either. I think it’s because people have a sense of duty. Voting in important general elections is just what you damn well do. And yes, there’s the bit of kidding yourself to believe that you make a difference, and there’s the bit of wanting to seem like an honorable person to the people around you. But I do think that many people have a sense of civic duty. And in particular for the things MacAskill discusses – elections, political rallies, choosing what to eat – these kind of feelings of duty matter even more.
Maybe this taking into account our effect on other people’s wellbeing is what people should do, not what they actually do. And that is also the limitation of MacAskill’s book: He can prescribe us how to act given however altruistic we are, but he cannot describe how large groups of people actually act.
And in this way he’s diametrically opposed from how economists usually try to argue. This could be the contribution of moral philosophy in a book that else reads mostly like economics.
Effective Altruism is an argument for strict rationality in your giving. But I think it’s ok to strike a balance between rationality and personal involvement. And that is because we are at once altruistic and we also derive utility from our giving. And giving to causes I’ve seen first hand, I get a lot more utility from.
People also probably have an intrinsic preference for balancing highly abstract, rational altruism and very concrete, routine, human-interaction-based, contextual altruism. You might work for a central bank and think, “My work helps mitigate recessions and avoid the next financial crisis; and through that my country will be richer and be able to help more poor people.” And you might well be right about that. But many people might still do something concrete on the side, whether that is volunteering for a homeless shelter, working with refugees or having an “adopted” child in Africa. And maybe the fact that people do the second kind distracts them from the first kind. But I think people enjoy the second, more direct, altruism more. And I think that’s ok. MacAskill is right to point out that we should compare alternatives and be rational about it. But everybody strikes their own compromise.
In the end, it’s about being compassionate without feeling guilty. When I traveled in India, I was overwhelmed. I saw begging children and skinny men drove me around in bicycle rikshas for very little money. A good recommendation I’ve heard is to give little everyday. Don’t always hold back and then give 50 euros to that begging girl with the pretty green eyes or the man with little children who tells you his sad story. Instead, I set myself a budget (a good tip a I got here) and then I gave that out in little chunks.
MacAskill response might be that both of these strategies are wrong and instead I should have given to the most effective charity (such as Give Directly). To which I have no good response apart from that it’s really hard not to help people whose suffering you see before you.
People have an inner wish for altruism. To encourage this is the goal of much of childhood education, religion and cultural ceremonies. But that’s not what MacAskill has any arguments for. He needs to take this as given and cannot tell us how altruistic we should be.
I also read this book as an endorsement of randomized control trials and development aid to poor nations in general. And given that these are two things that Angus Deaton disagrees with, I read it as an opposition to Angus Deaton’s views.
I really like this bit (added emphasis):
Because cash transfers is such a simple program, and because the evidence in favor of them is so robust, we could think about them as like the “index fund” of giving. (pos 1604-1605)
“Earning to give” is an interesting concept. But this line of thinking can easily be made extreme. Why not rob a bank and spend all of that on malaria bed nets? Or kidnap a politician and ask for 100 million to be spend on deworming.1
Similarly with his good discussion on the effects of choosing to be a vegetarian. Again, he shows a real economist’s skills by discussion the general equilibrium effects and shows estimates for how much supply falls when we reduce demand. But this position, too, if taken to its extreme is easy to lead ad absurdum. If we really just optimize over the one thing “Eating as few animals as possible”, then why not go on a killing spree and reduce the number of humans eating animals?
Instead I think our morality is and should be more complex and multi-faceted. We’re walking in a certain space and time and face constraints. You probably want to work somewhere, because it gives you purpose. And you want to do good both abstractly and directly. And people differ in how altruistic they are.
As economists we’re trained to describe how groups of people behave and we only rarely prescribe how they should behave. But that is what MacAskill does. His preferred way of how people should act is a poor explanation for how people actually do behave. Why do people over or underestimate risks, smoke, buy the wrong kind of insurance, buy stocks when they’re too expensive, take on too much debt and why do they act altruistically? He cannot explain any of this and it’s not his goal. Instead he does something that economists rarely offer: He shows how a rational person should behave morally given their preference for altruism.
My strongest criticism of the book is the following: Altruism is – and should be – just one part of many in a well-rounded person’s life goals. Yes, it’s a particularly important one that we should encourage in our children. But there are many, many other things to our life and maximizing over only one thing – altruism – seems dangerous to me.
After finishing this review, I came across this interview (in German) by the Swiss Tagesanzeiger with MacAskill where is asked exactly this. His response is that property rights should be protected and that Effective Altruism is about making the best decision given one’s constraints. Just optimizing no matter what he calls “primitive utilitarianism”. ↩
Good post by Ben Casnocha on why many very rich people work so hard:
Status. I believe the quest for status drives the behavior of the “post-economic” population to an extreme degree—people for whom there is there no economic imperative to work—and, for that matter, most of the rest of us, too.
And that horse race is a zero-sum attention game.
Tyler Cowen argues that status isn’t all zero-sum, but instead talking about one’s achievements is
“a way of processing the self.”
Casnocha then goes on and says,
But the hit doesn’t last. Like a drug, status is insatiable.
I would add that it also has a high depreciation rate.
Wall Street titans, Hollywood moguls, and tech billionaires do not physically duel. And they’ve often made so much money that they all have nice watches and cars and houses. But they do continue to race each other for prestige and power and other non-monetary status markers.
So instead, should we all relax and become baristas instead?
Casnocha says “No”, we should learn how to balance ambition and happiness and gives some recommendations of how to do that. Most of the recommendations evolve around ways of not getting lost in the rat race. But Ryan Avent (who Casnocha cites) might respond that, really, it’s a package deal and you cannot just move away without stopping what you do.
Peter Thiel and Blake Masters discuss in “Zero to One” how to successfully found a start-up.
They say the goal is to become a monopoly and they warn against a culture of competition. The aim is not to enter an industry and compete hard in it, but rather to found a new industry and be safe from competitors.
I liked the book and many of their thoughts. I think the following citation is great and I read it as a criticism of an alleged contentedness and satiation of my generation:
“Consider the trivial but revealing hallmarks of urban hipsterdom: faux vintage photography, the handlebar mustache, and vinyl record players all hark back to an earlier time when people were still optimistic about the future. If everything worth doing has already been done, you may as well feign an allergy to achievement and become a barista.” (p96)
Before reading this book, I would have placed Thiel in the libertarian corner so I was surprised to read a criticism of the idea of efficient markets:
“But the existence of financial bubbles shows that markets can have extraordinary inefficiencies.” (p100)
Also, this is fun:
“This is why physics PhDs are notoriously difficult to work with – because they know the most fundamental truths, they think they know all truths.” (p104)
They spend some pages defending auxiliary business operations such as marketing and sales:
“But advertising matters because it works. It works on nerds, and it works on you. You may think that you’re an exception; that your preferences are authentic, and advertising only works on other people.” (p127)
I’m doing research on the effects of automation on labor markets, so I was happy to see a discussion like the following:
“The stark differences between man and machine mean that gains from working with computers are much higher than gains from trade with other people. We don’t trade with computers any more than we trade with livestock or lamps. And that’s the point: computers are tools, not rivals. […] Properly understood, technology is the one way for us to escape competition in a globalizing world. As computers become more and more powerful, they won’t be substitutes for humans: they’ll be complements.” (p144)
and further,
“Why do so many people miss the power of complementarity? It starts in school. Software engineers tend to work on projects that replace human efforts because that’s what they’re trained to do. […] Just look at the trendiest fields in computer science today. The very term “machine learning” evokes imagery of replacement, and its boosters seem to believe that computers can be taught to perform almost any task, so as long as we feed them enough training data. […] Google Translate works […] because it has extracted patterns through statistical analysis of a huge corpus of text.” (p148-149)
and
“But big data is usually dumb data. Computers can find patterns that elude humans, but they don’t know how to compare patterns from different sources or how to interpret complex behaviors. Actionable insights can only come from a human analyst (or the kind of generalized artificial intelligence that exists only in science fiction).” (p149)
The book is surprisingly deep, non-standard and well-written. I found the parallels to academia striking. In some sense every new research project is a start-up. You own it, protect it and want it to succeed. If we follow Thiel’s advice in research, we should look for novel research projects to escape the competition. The advice doesn’t carry over completely, but I do think standing out is easier when following unconventional paths.
I also liked idea of being very aware of who the stakeholders in a project are. In academia that would be:
yourself
your coauthors
your supervisor and others like fellow PhD students that you regularly talk with about the state of the project and that keep track of its progress
everybody else
And I think the important thing is not to expect things from people from the wrong group.
And then there’s the issue of when you tell who about some good new idea. On the one hand, you want feedback. But if everybody knows your great new idea, then maybe they’ll go for it first. People tend to remember good ideas, but not who came up with them. And after a while, they think they came up with it themselves.
They write about this:
“If you find a secret, you face a choice: Do you tell anyone? Or do you keep it to yourself? […] Unless you have perfectly conventional beliefs, it’s rarely a good idea to tell everybody everything that you know. So who do you tell? Whoever you need to, and no more. In practice, there’s always a golden mean between telling nobody and telling everybody – and that’s a company.” (p105)
How radical to say: “Whoever you need to, and no more.” It goes against my nature. When I think I’ve figured something out I have a strong urge to tell everybody. But maybe it makes sense to pause, reflect on the idea first and to let the world know about it when the analysis is done and the story is ready to be told.
But then again, academics depend on their reputation and blatant stealing of ideas is not so frequent. And the process of telling people might even establish ownership. After all, start-ups can make you rich, but research offers insights.
Marina Keegan finished her studies at Yale in 2012 and died tragically in a car accident shortly after. She was beginning to write and a collection of her stories were published in 2014.
Her essay “The Opposite of Loneliness”” is a plea for optimism about what’s yet to come and against guilt about missed chances.
There’s this sentiment I sometimes sense, creeping in our collective conscious as we lie alone after a party, or pack up our books when we give in and go out – that it is somehow too late. That others are somehow ahead.
What we have to remember is that we can still do anything. We can change our minds. We can start over.
She expresses her feeling of belonging and security with her friends in college and her feeling of unity with the world. I think the German term “Geborgenheit” describes it best.
We don’t have a word for the opposite of loneliness, but if we did, I’d say that’s how I feel at Yale. How I feel right now. Here. With all of you. In love, impressed, humbled, scared. And we don’t have to lose that.
We’re in this together, 2012. Let’s make something happen to this world.
So, this was the setting – small data sets, manual computation, and noisy environments. These were the conditions under which almost all the statistical procedures that we use today were produced. (p19)
A formula is a simple presciption for computation, one that does not contain data dependent branches. (p21)
I think what this allows us to do, and what is basically the trend for the future, is that we are substituting computer power for unverifiable assumptions about the data. […]
Why use these techniques? I think the reason is clear. The cost of computation is ever decreasing, but the price that we pay for the incorrect assumptions is staying the same. (p26)
I don’t want to spend to much time on the Donald. Following your lead, I want to show some restraint. Because I think we can all agree that from the start, he’s gotten the appropriate amount of coverage befitting the seriousness of his candidacy.
I hope you all are proud of yourself. The guy wanted to give his hotel business a boost, and now we’re praying that Cleveland makes it through July.
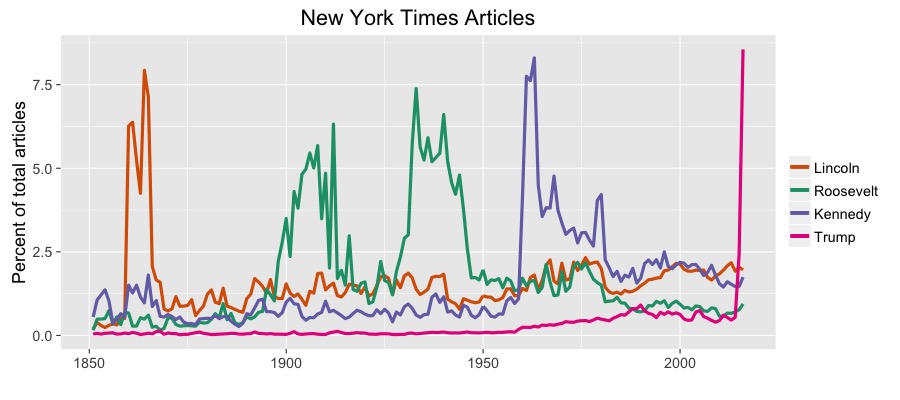 Source: NYT
Source: NYT