I just came back from the useR! conference in Toulouse which I enjoyed attending and which I recommend.
Some observations:
The conference was good mix of lectures, coding workshops and short presentations of new packages and papers.
The tidyverse has captured this community. Most code examples use the pipe and dplyr’s functions like select() or mutate() without explanation.
The vibe is closer to what I’m used to from academic conferences and it was less crowded and exuberant than NeurIPS.
I mainly visited talks on time series statistics, movement data and a few others.
Time series statistics
The tidyverts collection of packages for tidy time series analysis is fantastic and should be up on CRAN soon. It contains:
tsibble: An evolution of the tibble for time series purposes (itself an update to the dataframe). The tsibble makes it explicit which variable indexes time (e.g. “year”) and which groups the rows (e.g. “country”) and stores the information which frequency the data is running on.
feasts: New plotting tools tailored to the specific frequencies (e.g. seasons or weekdays) and decompositions of series into cycle and trends using different methods (STL, X11, …).
fable: Time series forecasting with many common methods and new visualization functionalities.
Other time series contributions:
A presentation on using random forests with time series data (paper, presentation). There was a lively discussion on how to create block bootstrap samples (overlapping? Moving windows? Size of blocks?) needed for the forest. The solution from the talk was to use a validation sample on which to test for the optimal block size.
For economists, timeseriesdb - developed at KOF Zurich - might be of interest. It provides a good way to store different vintages of time series and their metadata in a database.
The imputeTS package was presented with an application on sensor data. I could well imagine to use that package in a manufacturing analytics study, such as predictive maintenance. In these cases, you often have high-frequency measurements (such as by minute) for thousands of sensors, but the quality of measurements is hard to judge, outliers are common and sometimes missing data is even implicit (such as returning the last value again and again). The presenter pointed out that in these cases, the missingness is often correlated across variables (e.g. when there’s a factory shutdown, bad weather stopping data transmission, etc).
Anomaly detection got good coverage: The package anomaly (presentation), the stray package and a trivago real-world example with an interesting conclusion (presentation).
Spatial methods
Movement data is currently my favourite kind of data. It’s spreads across time and space, every data point is “weighty”, describing the repositioning of a giant machine or a group of people and you can use interesting methods to analyze such data.
I was therefore happy to see that there is a lot of work going on in creating packages for drawing maps and analyses of movement data. Presentations: 1, 2, 3, 4. The sf package was presented in two workshops (1, 2).
However, I’ve often found this topic quite difficult to start out with in R and I don’t think it’s become much easier yet. I’m still not convinced that I would go this route if I just needed to draw a quick map. A tool like Tableau takes care of all the underlying stuff such as guessing correctly that some column in your data describes US zip codes and draws the right map based on that.
Other: Packages building, data cleaning, big files
Jenny Bryan held a good tutorial on package development and she made her point really well that we should be writing packages much more often.
Hadley Wickham explained how the great tidyr package gets a facelift, renaming spread() to the more expressive pivot_wider() and gather() to pivot_longer.
I was quite impressed by the disk.frame package. It allows splitting a too-large-for-memory dataset into smaller chungs on the local machine and it only pulls in the columns you need. It also allows for quick staggered aggregations, such as calculating the sum of a variable for the different chunks and then taking the sum of that. Interestingly, that wouldn’t work for other functions such as the median.
I left academia for the private sector half a year ago. I handed in my dissertation and started working as an analytics consultant at McKinsey & Company, a large international consultancy.
I receive many questions about how that’s been, so I hope a blog post might answer most of the questions in one place.
What does an “analytics consultant” do?
We are management consultants, traveling to clients and working on projects that range from weeks to months. We bring quantitative firepower to teams and work on projects such as quantitative marketing, optimizing route networks, health care analytics, fraud detection or predictive maintenance. We use many different techniques, such as random forests, time series forecasting, optimization, network analysis, webscraping or deep learning.
Our studies are often full analytics studies from the start, and then using optimization or machine learning (ML) is more fundamental than “sprinkles on the top”. But it’s true that most of our time and many of our highest-value activities are “simple arithmetic”, such as collecting the right data, cleaning and merging datasets, calculating KPIs or writing a dashboard. I also spend a lot of time on tasks such as writing presentations, maintaining Excel sheets and calls and meetings with clients.
Why I switched
I decided to give the private sector a try for several reasons:
I really like coding. I’d like to get better at it and it’s something that might be valued more in industry than in academia.
I want to apply data science in a real-world setting (not least to find out if its all just a hype).
I found research very satisfying, but I don’t want to specialize on one topic. My dissertation touched many areas and the demands of academia would likely have made it necessary for me to be more focused.
It’s a cliché, but the thing I like most about my job are the people. My colleagues are inspiring, fun and highly motivated.
People are very friendly and sociable in the business world and consulting attracts people with good “verbal and social” skills.
2. Teamwork
You can make fast progress when teams work well together. And it’s not as bad to sit in a team room at 1 am if you’re in it together.
3. Speed of projects
I like that projects move faster and at some point they are actually done and you move on to the next one. This has a diversification effect, so even if a project is bad, it’ll be over not too far in the future.
4. Diversity of projects
The variance between projects is huge, because they can differ along so many dimensions: Industry, function, colleagues, place.
For me, it’s a good way to learn about the data science landscape and to see where my skills might be most valuable.
5. Being challenged
In academia you pick your own subject, methods and execute on your own speed. But being thrown into new topics is also activating and stops you from becoming complacent.
6. Feedback
Consulting encourages a strong feedback culture. It’s common to have feedback talks every two weeks. This is very helpful: It’s hard to judge on your own how you’re doing and it means there won’t be any surprises after the project is done.
7. Compensation
And yes, you’re better paid.
Advantages of academia
1. Freedom
In academia, I had the freedom to pursue my own projects and that’s something I miss in the private sector. Projects are initiated at much higher levels in the hierarchy and in junior roles you’re executing them.
In contrast, economics research is not very hierarchical. You are free to pick your topics and you pitch your ideas to anyone.
2. Ownership
At universities, the outputs of your work are public. Almost everywhere else – and especially in consulting – you might have accomplished cool things, but few people will know about it.
Academia is much more like running your own startup. You bear the risks, but you also reap the benefits. The downside is that you’ll have to live with the existential fears: “Will I publish my paper well?”, “Will I get tenure?”, …
3. Following rabbit holes
Management consultants live and breathe opportunity costs. This keeps you on your toes to keep making progress towards the target.
But this absence of slack means that what you learn and what you code is determined by what your project needs right now. You don’t just play detective and work on whatever interests you. In academia, new knowledge is the goal and you have to try many ideas and projects to find what has potential. Most private sector jobs are not “unicorn jobs”.
4. Work hours
I don’t think that I worked much less in academia. But work vs. leisure is much more sharply separated in the private sector.
When and how you work is largely out of your control in consulting and that’s a downside. In research, you have self-determined work hours. You might think it’s an advantage to push hard during the week and then to have the weekend off, but - at least for me - that’s not true.
On net
It’s maybe a bit exaggerated, but I would say that the private sector is more conducive to happiness, but research is a better way to find meaning (see here) in life.
How to apply
As economists, we’re very well prepared for data science jobs. We know econometrics, statistics, mathematics and we have internalized most MBA knowledge (e.g. accounting, corporate finance, marketing). We know how to manage long projects, work independently and be convincing in communicating our results.
However, we’re not obvious hires for data science positions. Many people conflate economics students with business majors and might not consider us quantitative enough. It’s not clear to employers that we know ML or that we can program.
I would recommend to learn R or Python. Nobody uses Stata or Matlab (or Julia, EViews, …). You should know one of the two languages reasonably well to be able to start coding on unfamiliar subjects quickly.
You’ll be expected to learn other languages or software soon, too. For example, I’ve learned VBA, Alteryx and Tableau since I started and none of that I’d used before. But I think it’s important to know R or Python, so that you’re productive from the start and that you can show that you can actually code.
On the ML side, the first step is to actually learn about it. An economics program doesn’t teach you machine learning, so you need to look elsewhere. I recommend online courses, checking for courses at your own computer science department or trying Kaggle competitions. A great way to learn about it and to show that you know it is to apply ML in your research.
Given that the outputs of our academic work are public and that you might have time to pursue side projects, it’s a good idea to create public artifacts. It makes sense to take this into account early in your PhD when choosing research projects. I wrote papers with text mining and webscraping, partly because I wanted to learn about these topics. Having written a paper like that is great for your application, because it’s a public output that proves that you know the subject. I’ve explained my patent paper in most job interviews and it was very helpful.
Because outputs in the private sector are not public, the next best proxy is your work experience and years in your PhD often don’t count. Public artifacts are marks of your skill that can compensate for lack of work experience.
When deciding where to apply, it’s important to consider the framework in which a firm operates. So if you work for a consultancy, then you’re a consultant first and a data scientist second.
Conclusion
I’ve enjoyed the whole experience and I’m happy with my choice. But there are also things I miss about academia.
I attended the NeurIPS (recently renamed from NIPS) conference this year and here are some observations:
I find it remarkable how for many people machine learning is equivalent to deep learning and deep learning is equivalent to computer vision.
Susan Athey talked about causal inference. She’s been doing a lot of work combining econometrics with machine learning, but it was very interesting to see this presented from the other side of the fence. When she asked who knew about instrumental variables, a reasonable number of hands (maybe 5% of a very large crowd) went up.
Edward Felten (Princeton) talked about how experts should talk to decision makers. Basically, don’t come with the “truth” and don’t provide “just the facts”. Structure the decision problem by inquiring about the decision makers preferences and provide information and an option menu of recommendations based on that.
Many of the sessions touched on economics: There were papers on market design, value function iteration or - more close to home - on the social effects of automation.
Differences to economics conferences:
Many more consumers than producers of research
Different demographics: Younger, more nerdy, fewer women, more Asian
Fewer parallel sessions, instead “tutorials” (really lectures) by famous people that last 1.5 hours
Videos/GIFs on slides. Works suprisingly well and engages people. Examples include simulations of how fruit flies move, 3d shapes circling around, bubbling formations of networks
The anthropomorphizing is a bit weird: They say “The algorithm should be able to reason about its own uncertainty”, instead of “We need accurate standard errors”
The money involved is different. We don’t have huge recruiting parties by Uber or have Yo-Yo Ma lead a session on the intersection of music and deep learning.
Montreal is the way I wish France was. People are laid back and cosmopolitan. Everything is in French and people switch between languages without effort.
Keeping up the tradition of the last two years, I’m again providing a list of my 10 favorite books this year.
In between finishing my dissertation, starting a new job and moving to a new city, I read less this year. I was worried that I would have almost no time for reading in my new job, but that hasn’t turned out to be the case. The weekend, late nights in hotel rooms and downtimes while traveling still provide many moments to read.
So here are the books I liked most this year (but which were not necessary published this year) in reverse order:
“Prohibition: A Concise History”, by W. J. Rorabaugh. This book shows that alcohol has not always been socially acceptable.
“Steve Jobs”, by Walter Isaacson. It’s incredible how intimately Isaacson is covering his life. I also enjoy it as a history of the 90s and 00s, a time I lived through.
“The Story of Art”, by E.H. Gombrich. I love this book. This is how to write about art. (Here, too, get the print version.)
“The Internationalists”, by Oona Hathaway and Scott Shapiro. This builds on years of scholarship, but the authors explain concepts in an accessible manner. Which other book would discuss the ideas of Grotius, Carlo Schmitt and Sayidd Qutb? This is a book that has changed how I view the world. A piece of their conclusion:
The example of the Internationalists offers a hopeful message: If law shapes real power, and ideas shape the law, then we control our fate. We can choose to recognize certain actions and not others. We can cooperate with those who follow the rules and outcast those who do not. And when the rules no longer work, we can change them.
Of the 748,584 polling stations about which we have data on building conditions, nearly 24% report having Internet and a similar number report having “Landline Telephone/Fax Connection.” 97.7% report having toilets for men and women. 2.6% report being in a “dilapidated or dangerous” building.
The current scandal demonstrates the value of the business intelligence/business analytics functions within companies. We were told that Facebook first realized that certain metrics were showing unusual trends, and upon investigation, they discovered the bugs.
This is entirely believable. That’s what happens when you have good data reports. They surface anomalies.
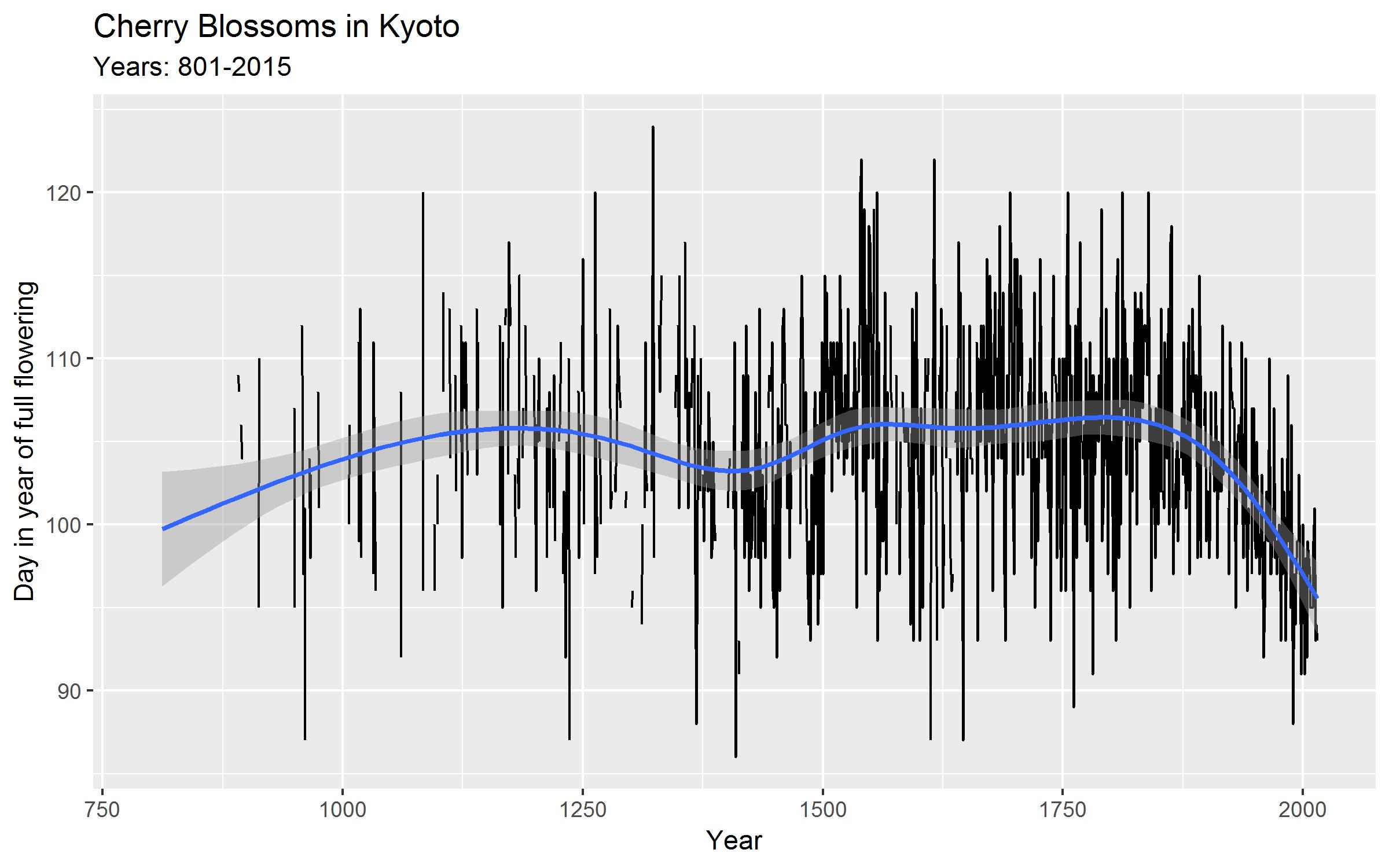
Cosma Shalizi offers a course with great name “Data over Space and Time”. As part of this course he uses data on the first day in the year that the cherry trees in Kyoto started blossoming. This data was collected by Yasuyuki Aono and coauthors.
Let’s check it out:
library(tidyverse)kyoto<-read_csv("http://www.stat.cmu.edu/~cshalizi/dst/18/data/kyoto.csv")ggplot(kyoto,aes(Year.AD,Flowering.DOY))+geom_line()+labs(title="Cherry Blossoms in Kyoto",subtitle="801-2015",x="Year",y="Day in year of full flowering")+geom_smooth()
Note the earlier blossoming of trees at the end of the sample which is a sign of rising temperatures.
Every graph in the AER since 1911 and paper. I’ve also found that economists heavy use of linecharts is quite atypical. Outside academia, other formats such as barcharts are much more common.
I was very impressed by this podcast episode of 80,000 hours interviewing Eva Vivalt. I didn’t expect to find meta-analyses interesting, but they are! One of my favorite bits of insight: If we asked researchers about their priors about what the results of a research project will be (DellaVigna-Pope style), then null results suddenly become interesting and worthy to publish. I also liked this blog post by Ricardo Dahis discussing the framework for meta analyses.
Sometimes a book is so good so that I really want to write a review, but I’m not sure I have anything substantial to add. That was the case for me reading Steven Pinker’s new book “Enlightenment Now: The Case for Reason, Science, Humanism and Progress”. There’s very little in his chain of argumentation that I could attack. Very frequently, I thought, “But how about X?” and that X was usually what Pinker addressed next.
In the book, Pinker argues that humanity has made progress in almost any measurable way. In his previous book, “The Better Angels of Our Nature”, he showed that the prevalence of violence in human lives has fallen strongly over the course of history and that this trend continues.1 In the new book, he widens his argument to include all areas of what he often calls “human flourishing”: Poverty has fallen and people live longer, healthier and happier lives. Wars have become more rare, existential risks are manageable, the world is becoming more democratic and we can handle risks to our ecological system. The coverage of civil rights has kept expanding to include women and minorities.
The book is dense in data and well argued. I really enjoyed it and agree with most of what the author writes. Most of the trends I was aware of, but I found his discussions of some issues (inequality, ecology, nuclear energy) refreshingly different from the takes I usually read (in particular in Germany) and well-founded. I hope this disclaimer removes the negativity bias (also discussed in the book) from the rest of this review.
II.
In a book that covers almost everything, it’s easy to attack something that’s missing.2 I want to focus my review on the core of Pinker’s argument which is (all the keywords are in the subtitle to his book):
Things have gotten better (progress!) for humanity in almost all measurable ways.
That’s because humans use reason and science to accumulate more knowledge and solve problems.
Associated with the increase of rational thought in our lives is a rise in atheist internationalist altruism (humanism).
Because this system of belief of reason/science with humanism has yielded the best results for humanity, we we should celebrate it and promote it further.
The twist in his argument is that there’s a divine coincidence: The institutions and the belief system that we like best (rational thought, a reduction of the role of religion in our lives) just happen to be what achieves the best outcomes.
But that’s a shallow defense of democracy and civil liberties.3 Aren’t there values and principles that we hold dear, even if they did not lead to the best economic outcomes?
Henry Kissinger defended the West’s personal freedom, democracy and free markets during the Cold War by arguing that this is the better system of belief, even if it hadn’t led to better economic outcomes than communism (Ferguson, 2016). At the time, the alternative that communist countries might grow more than free-market economies was taken seriously. Even leading economists expected the communist countries to overtake the Western countries in economic terms eventually.
A striking twist is then the rise of China. This is a country without democracy that has pulled off an incredible reduction of human poverty for a huge number of people. Using Pinker’s line of argument that should lead us to take authoritarianism seriously as a morally correct system.4
The problem is that China introduced economic liberties, but not political liberties. On the other side of the spectrum is Soviet Russia under Gorbatshev. William Taubmann’s “Gorbachev: His Life and Times” chronicles well how Gorbachev worked hard to introduce political freedom in the Soviet Union, but didn’t recognize the importance of economic freedom. The communist leadership was well aware of the shortage of consumption goods and the massive inefficiencies in the Soviet economy, but Gorbachev considered political freedom more important and didn’t trust free markets. It’s not that Gorbachev was ignorant of the economic troubles, but that the solution didn’t seem to be a liberalization of economic life.
Sadly, neither China or Russia delivered real freedom. So what do we conclude? People in China and Russia are better off than they were some decades ago and that’s something to applaude.
But I think the West’s model of democracy and personal freedom are superior, if they didn’t yield the best outcomes. Milton Friedman discusses this in depth in “Capitalism and Freedom”. He argues that economic and political freedom go together, that only if you are economically free you can hold views that are different to those of the government. He gives the example of a dissident who – in a centralized system – couldn’t even finance his daily life or his campaigning. This would suggest that economic freedom might beget political freedom. But as the case of China shows, that’s not always the case.
In the end, Friedman does not argue from economic or material grounds, but in terms of ideology:
The heart of the liberal philosophy is a belief in the dignity of the individual, […]. This implies a belief in the equality of men in one sense; in their inequality in another. […] The liberal will therefore distinguish sharply between equality of rights and equality of opportunity, on the one hand, and material equality or equality of outcome on the other. He may welcome the fact that a free society in fact tends toward greater material equality than any other yet tried. But he will regard this as a desirable by-product of a free society, not its major justification. (“Capitalism and Freedom”, Chapter 12: “Alleviation of Poverty”)
And Pinker falls into exactly that trap in this book.
III.
Pinker likes to cite internationalism as a goal, that obviously it’s irrational to weight people’s well-being less than that of people in your country. But that’s not obvious to most people and that’s not how most people act.
Pinker writes (my emphasis):
Ideologies that justify violence against innocents, such as militant religions, nationalism, and Marxism, can be countered with better systems of value and belief. (Chapter 23)
But it’s just the problem of belief systems that they determine what’s good and bad. It’s a circular argument to use evidence that there’s lot of progress according to and due to that value system to make a case for exactly that value system.
Say, your value system tells you that you want to maximize the number of paper clips in existence on earth. So if the number of paperclips in existence has increased: Voilá - that belief system is great!
A response to my criticism might be the following: Reason and science are critically not a belief system, but the correct way of learning about the world.
OK, granted. But humanism is a belief and value system. And scoring humanity’s achievements yields very different assessments through the lens of humanism than it would through alternative world views. If your religion tells you that life starts with the inception, then the increase in pregnancy terminations is an incredible disaster. If you’re a nationalist who believes that people’s and races are a thing and should be kept separate, then globalization, intermarriage and the rise in cosmopolitanism are a big problem.
Pinker singles out those two world views (religion and romantic-nationalism) and takes them apart one by one. He writes that there is “probably no god”, so basing our morality on religion leads us to the wrong place. He writes that romantic-nationalist inspired by Nietzsche misunderstand human nature.
And maybe he finally wins that way, because we can reason about our value systems and test the premises they are built on.
V.
This book is a clear-sighted summary of the achievements of economic growth. It synthesizes vast amounts of data and research and makes a much more grand case than comparable books.5
Sometimes a book is so good so that I really want to write a review, but I’m not sure I have anything substantial to add. Arguing for humanism on materialistic grounds bothers me, but it might be our best argument for it. Let’s be happy about the divine coincidence.
References
Carroll, Sean (2016). The Big Picture: On the Origins of Life, Meaning, and the Universe Itself. Dutton.
Ferguson, Niall (2016). Kissinger: 1923-1968: The Idealist. Penguin.
Friedman, Milton (1962). Capitalism and Freedom. University of Chicago Press.
Pinker, Steven (2012). The Better Angels of Our Nature: Why Violence Has Declined. Penguin.
Pinker, Steven (2018). Enlightenment Now: The Case for Reason, Science, Humanism, and Progress. Viking.
Taubmann, William (2017). Gorbachev: His Life and Times. Simon & Schuster.
And he showed what great outliers the two World Words were. ↩
For example, why isn’t the extinction of species covered? Isn’t that a case where there’s clearly no progress, but instead our economic expansion has done harm? ↩
Pinker also makes another case for democracy which is that it smooths out errors by individuals well. But that argument feels tacked on to his main point and is not supported by the same level of data and explanation as the main thrust of his argument. ↩
Pinker being Pinker he obviously also covers that case and writes that China today is already quite a more liberal and open society compared to some decades ago. But China is not a free, democratic country (Freedom House, for example, classifies it as “not Free”). ↩
In particular, I find it a great complement to Sean Carroll’s “The Big Picture”. ↩
There is a story about an old man which rheumatism who asked his healthy friend how he managed to avoid the malady.
“By taking a cold shower every morning all my life” was the answer.
“Oh! exclaimed the first, “then you had cold showers instead.”
That’s from “One Two Three … Infinity”, by George Gamow, first published in 1947.