We’ve updated our paper on automation patents which you can find here and here (and see here to play around with the data). In short, we identify automation patents based on their patent texts and create this new dataset:
Background
Reading Erik Brynjolfsson and Andrew McAfee’s “Second Machine Age” three years ago got us interested in the topic. We were looking for data on how automation had advanced over time and across industries, but none of the existing proxies quite satisfied us. The idea to use patents came after reading Acemoglu et al. (2014) for a class which made us aware of patents as a data source.
It was striking that (almost) no researchers so far had made use of the actual patent texts. Instead, people use patent metadata such as citations (see e.g. here and here).
We were lucky that Google provides a bulk download page for patents (also see these codes). One of the tasks that took us the longest time was to write a parser to extract and clean the text sections for all patents from the titles, abstracts and text bodies of the patents. That was tricky as those are 336 GB of text which makes storing and retrieving the documents an issue. The parsing step took a week on a server where eight cores ran in parallel.
We then trained a naive Bayes algorithm on a sample of patents that we classified ourselves (using these guidelines).
Here’s an example of such an automation patent:
So the patent with the name “Automatic Taco Machine” was invented by one Barry Brummet from California and is assigned to (owned by) Taco Bell. He applied for the patent in 1994 was granted it in 1996. It cites other patents such as this one. Using this data, we can also check who cited the “Automatic Taco Machine”. We find that up until 2010 it was cited a total of 11 times (for example by this, this and this patent).
Even in the title of the “Automatic Taco Machine” you have the word “automatic”, so this is an easy patent to classify. Other words in the patent text that were important in classifying it as automation were are “removable”, “storage”, “acceptable”, “support arm”, “assist”, “communicate”, “measures”, “processor” and 179 others.
Next, we checked where every patent is likely to be used (not invented). For this, we used Brian Silverman’s concordance tables. For our example, we find:
We then matched our industries to US commuting zones (with the CBP) and get the picture at the top of this blog post. It shows the number of automation patents that can be used by a single worker in each of these commuting zones. In the earlier years, the rust belt saw a lot of automation patents, but this has become much more spread out and diffuse over the years.
Our empirical results are the following:
Between 1976 and 2014, about 2 million automation patents (out of 5 million patents in total) were granted.
The share of innovation concerned with automation rose from 25% in 1976 to 67% in 2014.
There was more investment in robots and computers in industries with more automation patents. Those were also industries where in 1960 more people worked in routine tasks.
Local labor markets (commuting zones) in the US where more new automation patents could be used experienced increases in employment.
Automation led to a loss in manufacturing employment, but this was more than compensated by a rise in service sector employment.
If you’ve become curious about the paper, you can find it here.
References
Acemoglu, D., U. Akcigit and M. A. Celik (2015). “Young, Restless and Creative: Openness to Disruption and Creative Innovations”. NBER Working Paper No. 19894.
Autor, D., D. Dorn, G. H. Hanson, G. Pisano and P. Shu (2016). “Foreign Competition and Domestic Innovation: Evidence from U.S. Patents”. NBER Working Paper No. 22879.
Bell, A., R. Chetty, X. Jaravel, N. Petkova and J. V. Reenen (2017). “Who Becomes an Inventor in America? The Importance of Exposure to Innovation”. NBER Working Paper No. 24062.
Bessen, J. and R. Hunt (2007). “An Empirical Look at Software Patents”. Journal of Economics and Management Strategy, 16(1): 157–189.
Brynjolfsson, E. and A. McAfee (2014). “Second Machine Age”. Norton & Company.
Katja Mann and Lukas Püttmann (2023). “Benign Effects of Automation: New Evidence From Patent Texts”. The Review of Economics and Statistics
Silverman, B. S. (2002). Technological Resources and the Logic of Corporate Diversification. Routledge.
So today, let’s discuss a new paper by Michaels and Rauch which uses a fantastic historical case to investigate this debate: the rise and fall of the Roman Empire.
The Romans famously conquered Gaul – today’s France – under Caesar, and Britain in stages up through Hadrian (and yes, Mary Beard’s SPQR is worthwhile summer reading; the fact that Nassim Taleb and her do not get along makes it even more self-recommending!).
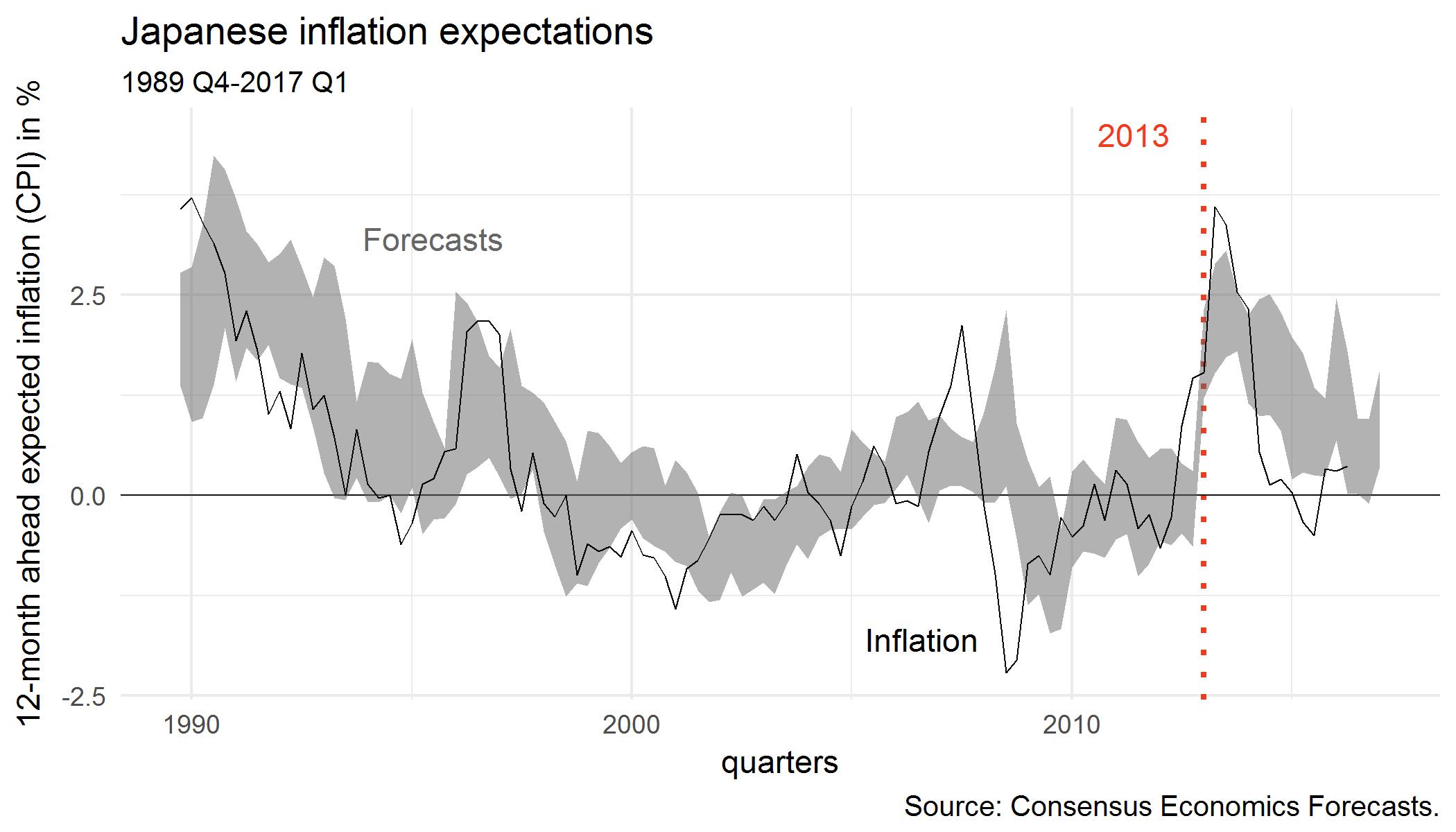
I’m currently working with macroeconomic forecasts by banks and research institutes (CEF). When I checked out inflation expectations, the following figure caught my attention:
The black solid line is quarterly Japanese consumer price inflation (CPI). The gray areas are two standard errors above and below the mean forecast. (Forecaster dispersion is a reasonable proxy of how uncertain forecasters are.) I overlaid the 12-month ahead forecast with the subsequent realizations.
The jump in inflation expectations in 2013 (Abe won in December 2012) is quite striking. And that effect seems to have abated somewhat since then.
References
Bachmann, R., S. Elstner and E. R. Sims (2013). “Uncertainty and Economic Activity: Evidence from Business Survey Data”. American Economic Journal: Macroeconomics, 5(2): 217-49.
… [T]he pure empirical estimates, that militarization reduces crime without any objectively measured cost in terms of civic unhappiness, are quite mind-blowing in terms of changing my own priors.
New NBER working paper by Stefania Albanesi, Giacomo De Giorgi and Jaromir Nosal:
Our analysis suggests a reassessment of the role of growth in the supply of subprime credit in the 2001-2006 housing boom and in the 2007-2009 financial crisis. We find that most of the increase in mortgage debt during the boom and of mortgage delinquencies during the crisis is driven by mid to high credit score borrowers, and it is these borrowers who disproportionately default on their mortgages during the crisis. The growth in defaults is mostly accounted for by real estate investors.
Lucrezia Reichlin presented yesterday at the EEA’s annual meetings “Big Data and Macro Econometrics”. (Here are some older slides from a similar talk.)
She recommends using a large number of macroeconomic series with dimension reduction, such as Lasso and Ridge regression. These methods are intuitively appealing and work well. Packages such as glmnet automatically choose a mix of these two methods based on cross-validation.
Unfortunately, there was no discussion on the difficulties of applying resampling methods with aggregate time series. In macro, the time series dimension of the data is always shorter than we would like it. You might have 50 years of data and if you’re lucky that comes in quarterly or monthly frequency. And even if you extend your series back a couple of decades or across countries, our number of observations doesn’t become very large.
Instead, it’s becoming easier to find more variables to describe the same economy. We can use consumer surveys, scanner data or scrape the web for a more detailed view of the economy, but our number of observations grow only slowly. And frankly, the opposite would be better: I would rather observe only 10 or 20 variables from one economy over a really long time (or equivalently from many similar economies) than hundreds or thousands of variables about only one economy.
The fact that our number of observations grows slowly limits the scope for slicing samples into training, cross-validation and test sets. Thus, the focus in macroeconometrics is a lot more on dimension reduction than it is on an unguided search for patterns.
Sarah Bakewell has written “At the Existentialist Café”, a biography of existentialist philosophers intertwined with an overview of their thought.
The author imagines them like this (her emphasis):
These philosophers [Heidegger and Sartre], together with Simone de Beauvoir, Edmund Husserl, Karl Jaspers, Albert Camus, Maurice Merleau-Ponty and others, seem to me to have participated in a multilingual, multisided conversation that ran from one end of the last century to the other. Many of them never met. Still, I like to imagine them in a big, busy café of the mind, probably a Parisian one, full of life and movement, noisy with talk and thought, and definitely an inhabited café.
Bakewell makes the jargon palatable and this is probably the book where I’ve taken the largest number of notes on my Kindle so far. I found the book gripping and couldn’t put it down. That was helped by the fact that the story takes placed during the first half of the 20th century and we follow the protagonists around as they cope with the catastrophies of those times.
And these philosophers came up with beautiful metaphors for the mind: For Heidegger, it’s a clearing in a forest. And more:
When he [Merlau-Ponty] looks for his own metaphor to describe how he sees consciousness, he comes up with a beautiful one: consciousness, he suggests, is like a ‘fold’ in the world, as though someone had crumpled a piece of cloth to make a little nest or hollow. It stays for a while, before eventually being unfolded and smoothed away. There is something seductive, even erotic, in this idea of my conscious self as an improvised pouch in the cloth of the world. I still have my privacy — my withdrawing room. But I am part of the world’s fabric, and I remain formed out of it for as long as I am here.
Her last chapter “The imponderable bloom” is a great piece in itself. She synthesizes the phenomenologists’ and existentialists’ theories and explains how their arguments entered our view of the world and our search for “authenticity”. We take pleasure in learning how irrational we are as piles of biases and preferences that can be quantified and predicted. Yet fundamentally our minds are free and constraining ourselves to anything else would be Sartre’s “bad faith”, she writes.
Bakewell finishes with this:
When I first read Sartre and Heidegger, I didn’t think the details of a philosopher’s personality or biography were important. This was the orthodox belief in the field at the time, but it also came from my being too young myself to have much sense of history. I intoxicated myself with concepts, without taking account of their relationship to events and to all the odd data of their inventors’ lives. Never mind lives; ideas were the thing. Thirty years later, I have come to the opposite conclusion. Ideas are interesting, but people are vastly more so.
Here are the workshops. I published this list last year and it was well-received. This year, I found it striking how many papers there are with a large number of coauthors.
So here again is my idiosyncratic and non-representative list of papers that caught my eye (not all seem to have drafts up yet):
The Yale undergraduate goes to work at McKinsey for two years, then comes to Harvard Business School, then graduates and goes to work Goldman Sachs and leaves after several years to work at Blackstone. Optionality abounds!